A Backend Mindset Beyond Jupyter: Serving XGBoost with Flask and Gunicorn
A fraud model worked in a notebook, but the real work started when it had to sit behind checkout. The useful backend pieces were validation, model startup loading, Gunicorn serving, traceable database records, score storage, and decision logs.
Hello, world.
I am making my engineering logs public today.
From time to time, I’ll post what I’ve been building, breaking, fixing, and everything in between. Usually, it’s a working log: some backend, some data, some architecture, some mistakes, some breakthroughs.
Today’s log is about integrating XGBoost into the backend.
Or more accurately, it is about what happens when a backend developer starts poking around machine learning and quickly realizes the model is only one part of the system.
At this point, most of my work has been around macros, automation, VBA, Python, backend systems, database design, application logic, and building apps. Data science has been getting louder recently, so I wanted to understand more of it from the inside instead of letting it stay as a buzzword.
So I built a small fraud detection pipeline.
The use case was e-commerce checkout fraud.
The idea was simple enough:
transaction comes in
→ store the transaction
→ prepare the features
→ call the model
→ return a fraud risk score
→ let the app decide what to do next
The model sat inside a checkout path, so the backend had to be fast, traceable, and careful with bad input.
I used XGBoost as the model. Why? We’ll get to that below. But I knew there was more going on underneath the backend.
In this case, fraud detection sits inside a checkout flow. That means the system has to be fast, predictable, and careful.
If it blocks a legitimate customer, the business loses money and annoys the buyer. If it lets a fraudulent transaction through, the business eats the loss.
So even though this was a machine learning experiment, I treated it like a backend problem first.
Database design mattered first
Database design matters.
I needed a clean way to store the raw transaction, the normalized feature values, the model output, and the final decision.

Keeping raw payloads, feature rows, model scores, and checkout decisions separate made the pipeline inspectable.
The raw transaction is what the app received.
The feature row is what the model actually consumed.
The model output is the score.
The decision is what the business logic did with that score.
Keeping those separate made the system easier to inspect. If a transaction was flagged incorrectly, no guessing. I wanted to trace the path from payload to feature mapping to score to decision.

A wrong decision could be traced back through raw input, normalized features, model score, and final checkout action.
I didn’t bury important state inside a script or let the model become a black box.
The notebook version was not the serving version
Well, the first version worked locally.
I trained the model. I called predict(). I returned a score from a Flask route. It looked fine in the notebook and fine in a local API test.
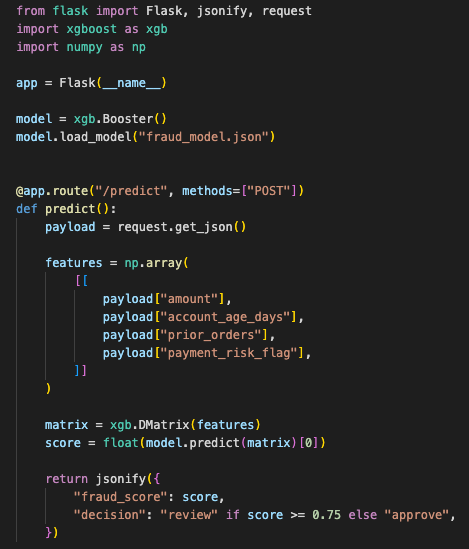
The first route proved the model could return a score. It did not prove the service was ready for checkout traffic.
Then I tried serving it like an actual endpoint.
That is where the problem showed up.
A notebook does not care about concurrent requests. A checkout flow does.
My first issue: loading too much work inside the request path.
The model file was being loaded too casually, as if each request was just another local script run.
That is fine when one developer is testing one request. It is not fine when multiple requests hit the service.

Loading the model inside the request path duplicated expensive work and made response time unpredictable.
The model loaded at startup
The model loading had to move out of the request cycle.
I reworked the Flask app so the model loaded when the application started. The route itself only handled validation, feature preparation, prediction, and response formatting.
Then I served it with Gunicorn instead of the basic Flask development server.

The model loaded during app startup. Requests reused the loaded model instead of paying startup cost each time.
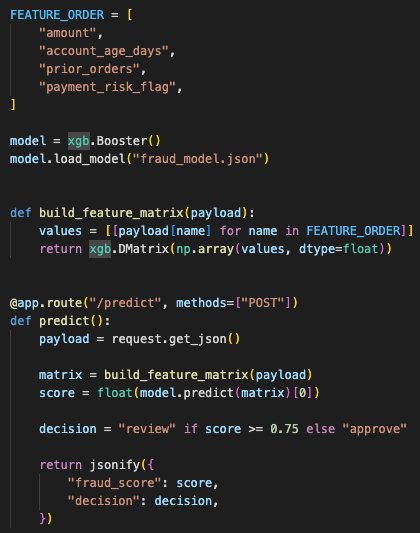
The app initialized the XGBoost model once and reused it across prediction requests.
First takeaway:
A model is not production-ready just because it can return a prediction.
It needs a serving layer.
Bad input had to fail before inference
Second issue: input quality.
In the notebook, the dataset is organized. The columns are there. Types are known. Missing values have already been handled. The model receives the exact feature shape it expects.
In an API, the outside world sends whatever it sends.
Missing fields. Strings where numbers should be. Nulls. Extra fields. Wrong formats. Bad assumptions from the frontend.

Bad payloads had to stop at the API boundary before reaching feature preparation or inference.
So I added request validation before inference.
The API had to reject bad payloads before they reached the model. I did not want the model silently accepting malformed input and returning a confident-looking answer from broken data.
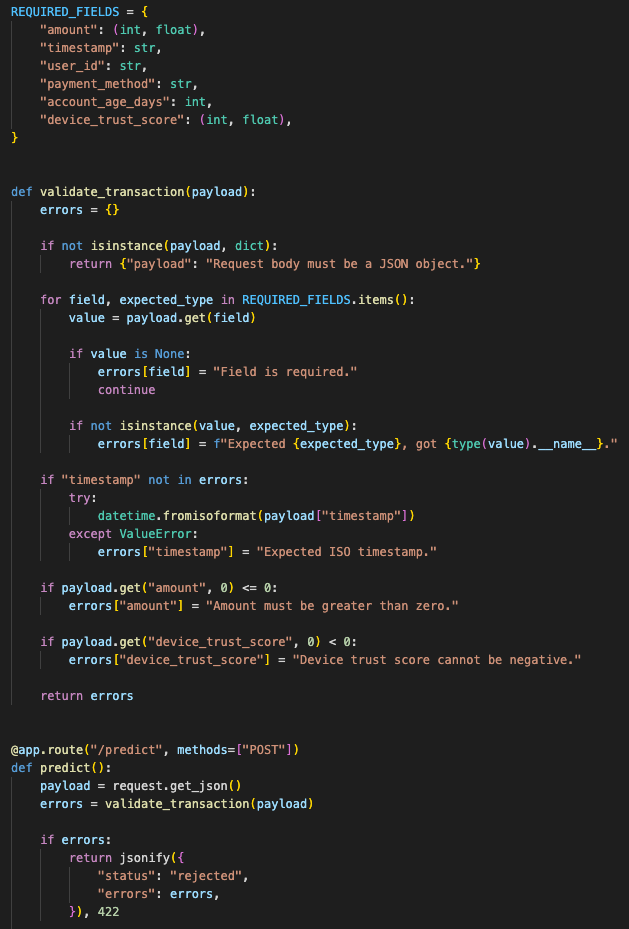
The validation layer rejected missing fields, bad types, nulls, and malformed transaction data before inference.
That is one of the more delicate parts of machine learning inside an application.
Bad input does not always crash. Sometimes it returns a number. And because the number looks precise, people trust it.
The database helped here too.
By keeping raw inputs, feature rows, scores, and decisions separate, I could debug the pipeline without guessing where the mistake happened.
The backend shape became something like this:
checkout payload
→ Flask API
→ schema validation
→ transaction record
→ feature preparation
→ XGBoost prediction
→ score record
→ decision rule
→ response to app
The backend stored the transaction, prepared features, reused the loaded model, stored the score, applied a decision rule, and returned the checkout response.
XGBoost fit the data shape
All fundamentals, which is the point.
The useful work was making the system boring enough to reason about.
Why use XGBoost?
Because the data was tabular. Transaction records are structured: amounts, timestamps, user history, order details, payment signals, account behavior. This is the kind of data where tree-based models are practical and fast.

The model consumed structured transaction features, not raw checkout JSON.
But the model choice was only one layer.
The more important engineering questions were:
- Can the API stay up?
- Can the payload be trusted?
- Can bad input be rejected?
- Can the database explain what happened later?
- Can the app call this without slowing down checkout?
- Can a developer debug a wrong decision?
That is where my backend background became useful.
Data science is still new territory for me, but the production concerns were familiar: inputs, outputs, database state, failure modes, request latency, deployment behavior.
Same old problems. Just with a model in the middle.
Result
That is probably the main thing I learned from this build.
Once a model starts influencing real application behavior, the system around it has to be clear. Validation. Traceability. Clean boundaries. A way to understand what happened when the output is wrong.
A notebook can prove that an approach might work.
A backend system decides whether anyone can safely use it.
Data science is interesting, but backend is the part that makes it useful.
Onto the next one. Let’s keep sharpening that edge.
First written on December 14, 2018.
Want to implement this architecture in your business?
Discuss Your Project