Agentic Inventory: Separating Stock Records From AI Decisions
Stockpile keeps inventory records inside a deterministic FastAPI system of record while routing AI reasoning through a guarded Next.js gateway. The model can analyze and propose, but stock mutations still pass through typed backend rules.
I’ve been building Stockpile, an AI-augmented inventory platform for small and mid-sized operators.
The use case is practical.
Inventory-heavy businesses do not need an AI chatbot pretending to be an ERP.
They need a system that can track stock, calculate risk, flag reorder problems, import messy product rows, and help owners make better decisions without letting the model corrupt the inventory database.
That last part matters.
Inventory is operational truth.
If the stock count is wrong, the business feels it fast: missed orders, dead capital, supplier delays, emergency purchasing, and staff manually reconciling what the system should have known already.
So I built the architecture around one rule:
The inventory backend stays the system of record.
The AI can analyze, propose, and format actions.
It does not become the database.
Two paths, one source of truth
The system has two paths:
standard inventory work
→ FastAPI system of record
→ tenant-isolated database
→ CRUD, bulk import, insights, sync, action execution
AI reasoning work
→ Next.js AI gateway
→ tenant authentication
→ rate limit
→ budget pre-charge
→ model routing
→ streaming or background job
→ JSON parsing
→ action proposal or forecast output
Standard inventory operations stay on the deterministic FastAPI path. AI reasoning goes through the gateway and returns proposals, forecasts, or structured output.
The first path is boring on purpose.
FastAPI owns the inventory records.
Each record has the fields the business actually needs:
tenant ID
SKU
product name
category
current stock
safety stock
burn rate per day
supplier lead time
unit cost
status
last updatedThe local build uses SQLite. The production-shaped path uses PostgreSQL if DATABASE_URL is configured.
That gives the project a clean dev-to-prod boundary.
SQLite is enough for local testing and demos.
PostgreSQL is the right shape for a real hosted inventory database.
The database layer hides that switch behind a small connection helper. If Postgres exists, it uses psycopg2 with RealDictCursor. If not, it falls back to SQLite with row objects.
The inventory router then uses an execute_query wrapper so each endpoint can run against both dialects.
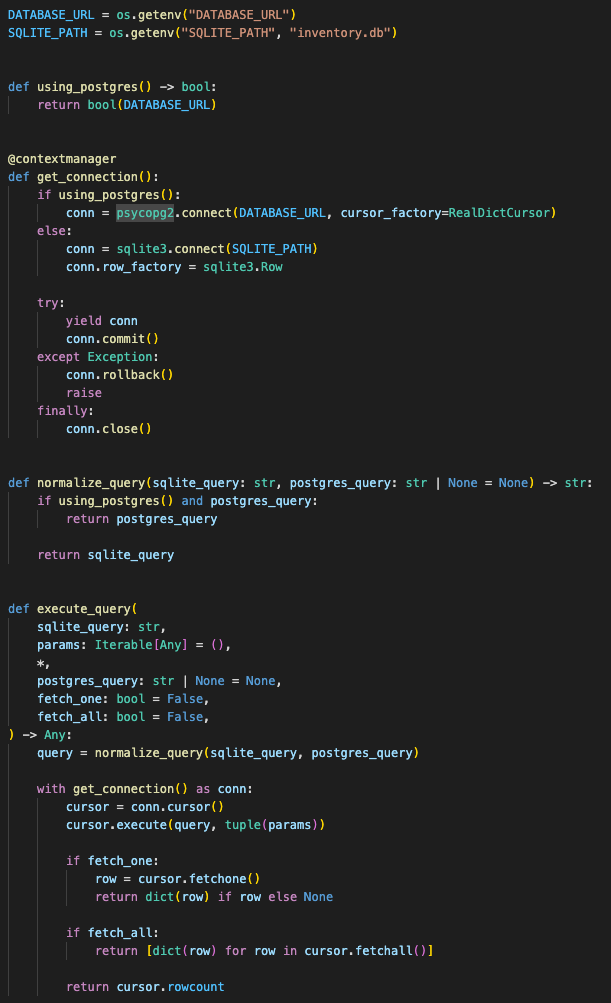
The wrapper lets the same route logic run locally against SQLite and move toward hosted PostgreSQL without rewriting endpoint behavior.
That wrapper is not glamorous.
It saves a lot of friction.
The same endpoint can run locally with inventory.db, then move toward a hosted Postgres database without rewriting the business logic.
Tenant isolation belongs in the backend
The schema is tenant-scoped.
The primary key is not just sku.
It is:
tenant ID + SKUThat matters because SKU collisions are normal. Two businesses can both have MAT-001, SOAP-001, or COF-ORG-LB.
The backend should treat SKU as unique inside a tenant, not globally.
Every inventory route requires tenant context through X-Tenant-ID.
The API dependency fails the request if the gateway does not provide a tenant ID.
The routes also filter every query through that tenant ID.
get inventory
→ tenant filter
get item
→ tenant + SKU filter
create item
→ insert tenant ID
patch item
→ update tenant + SKU
delete item
→ delete tenant + SKU
execute action
→ fetch tenant + SKU firstThat is the minimum boundary for a B2B inventory tool. Tenant isolation cannot live only in the frontend.
The backend also requires a gateway key header.
The intent is simple: the FastAPI system of record should be called through the Next.js gateway, not exposed as a loose public mutation API.
That gives the app a chokepoint.
The frontend and AI gateway can handle session logic, model calls, budget checks, and UI behavior. The Python backend stays focused on inventory correctness.
Status calculation stays deterministic
The second important boundary is status calculation.
The app does not let the model invent whether an item is healthy, warning, or critical.
The backend calculates that deterministically:
current stock <= safety stock / 2
→ critical
current stock <= safety stock
→ warning
otherwise
→ healthy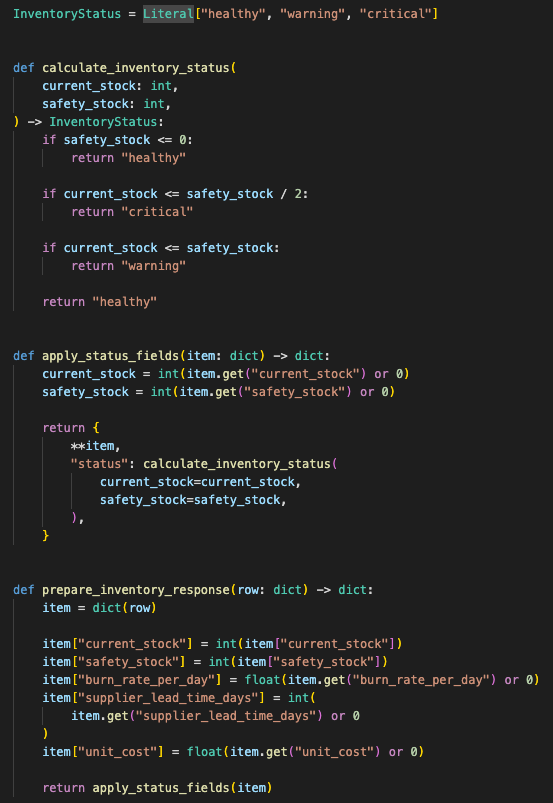
A model can recommend action. The backend decides the status field.
That rule is simple, but it prevents a lot of slop.
A model can recommend action.
The backend decides the status field.
That same idea appears in the insights endpoint.
The /insights route pre-computes business metrics without calling the LLM:
- Total capital locked
- Capital at risk
- Immediate action count
- Days until stockout
- Lead time deficit
- Recommended reorder quantity
The stockout logic uses current stock, daily burn rate, and supplier lead time.
If days of cover is less than lead time, the item becomes urgent.
That is inventory math, not language-model reasoning.
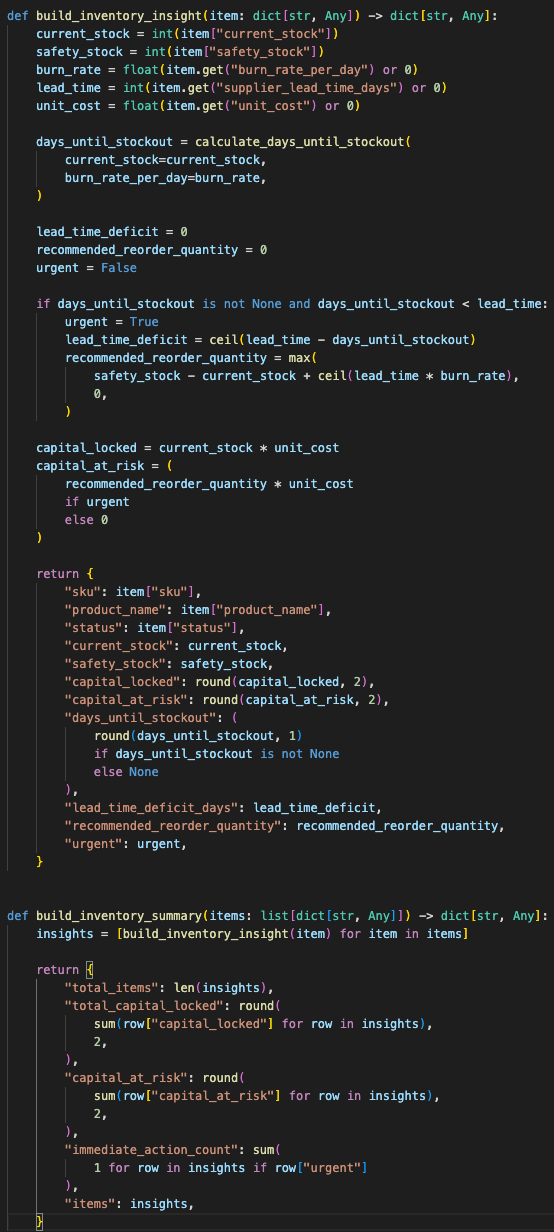
The backend calculates operational inventory risk directly instead of spending model tokens on basic stock math.
This is the part I care about for smaller operators.
A lot of businesses already know they have inventory problems. They just do not have a clean way to see the operational shape:
- Which items are close to stockout?
- Which items have money trapped in overstock?
- Which SKUs need reorder before the supplier lead time catches up?
- Which products changed after new orders synced?
That should not require an AI call.
The backend can calculate it directly.
The AI layer should sit on top of that.
Bulk import handles messy operational reality
Stockpile also has a bulk import endpoint.
That exists because real businesses do not onboard inventory one item at a time.
They have CSVs, spreadsheet exports, old POS dumps, and manually cleaned product lists.
A row-by-row frontend import can easily become accidental self-DDoS. If the user imports 500 items and the browser sends 500 separate POST requests, the system wastes time and creates failure points.
The /bulk endpoint takes a list of inventory items, validates each one, calculates status, inserts what it can, and returns per-SKU errors without killing the whole batch.
That is more useful than pretending every import is clean.
The system also includes a simulated external order sync.
It is not a real Shopify or Amazon integration yet.
The endpoint simulates the shape: pull recent order activity, deduct sold quantities, recalculate status, and return what changed.
That matters because inventory tools become useful when they react to sales movement, not just static manual counts.
I would not oversell this as a live marketplace integration.
It is a seam for one.
The AI gateway is the intelligence boundary
The AI path starts at the Next.js gateway.
That route is the intelligence boundary.
It does the work I do not want inside the system-of-record API:
- JWT or secret validation
- Tenant resolution
- Per-tenant/IP rate limiting
- Prompt size checks
- Model routing
- Budget pre-charge
- Streaming response handling
- Background job dispatch
- LLM JSON cleanup
- One retry on malformed action output
- Job state storage
- AI logs

The gateway guards expensive model work before it reaches the provider and keeps AI behavior outside the inventory system of record.
The model route is split into groups.
Route Group B is for action payloads.
That path tells the model to return only JSON:
{ "sku": "string", "action_type": "string", "quantity": number }or an array of those objects.
Route Group C is for heavier portfolio forecasting.
That path uses a stricter context rule and asks for JSON output based on the provided inventory dataset.
This is not because the letters matter.
The point is that action generation and portfolio analysis are different workloads.
A reorder action should be small and parseable.
A portfolio forecast can be slower and more analytical.
The gateway also enforces prompt length.
If the prompt is missing or oversized, it rejects the request before the model call.
That matters for cost and reliability. Inventory context can grow quickly. A user or bug should not be able to shove unbounded content into the model path.
The backend has a separate 50KB payload cap at the FastAPI middleware layer.
That protects the system of record from context stuffing and oversized mutation requests.
Again, not glamorous.
Necessary.
Budget enforcement runs before inference
The AI gateway has a Redis-backed budget ledger.
Before the model call, it estimates a worst-case cost and pre-charges the tenant’s monthly spend key.
If the pre-charge would push the tenant over the cap, the request is rejected before the LLM runs.
After the model call finishes, the gateway calculates actual usage and refunds the unused amount.
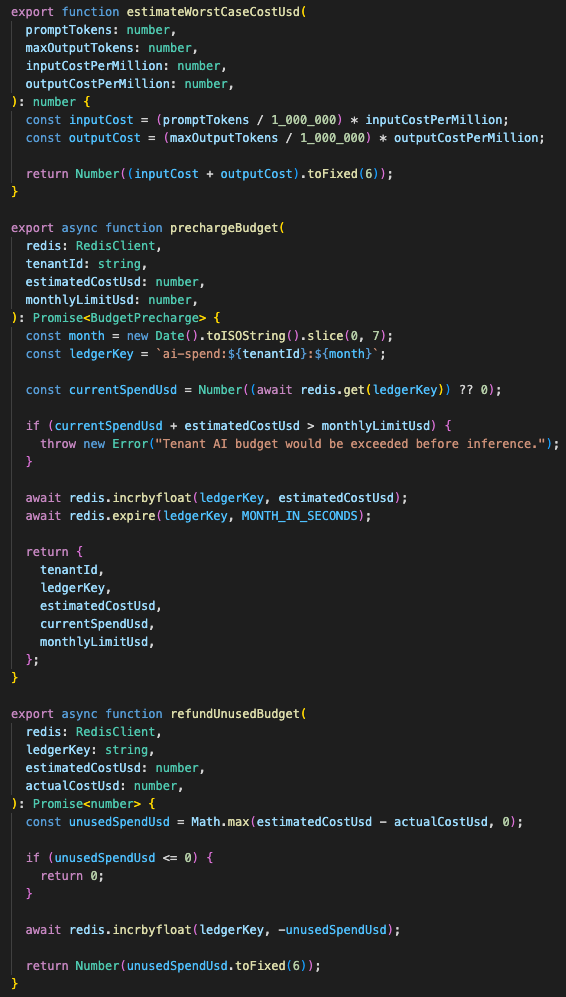
Pre-charge accounting protects the system from runaway model calls before the provider spend happens.
That is a better pattern than checking spend after the fact.
Post-call accounting is useful for reporting.
Pre-charge accounting protects the business from runaway calls.
This matters a lot in agentic systems because retry loops and malformed outputs can quietly burn money.
Malformed JSON gets one repair attempt
In the background-job path, Stockpile has a one-retry loop for brittle JSON.
The model sometimes returns markdown fences, missing keys, or a shape that looks right to a human but breaks automation.
The background worker tries to parse the response.
If Route Group B output is malformed, it appends a correction prompt and retries once.
Once.
Not forever.
That limit matters.
Infinite repair loops are how AI systems turn a small formatting issue into a billing problem.
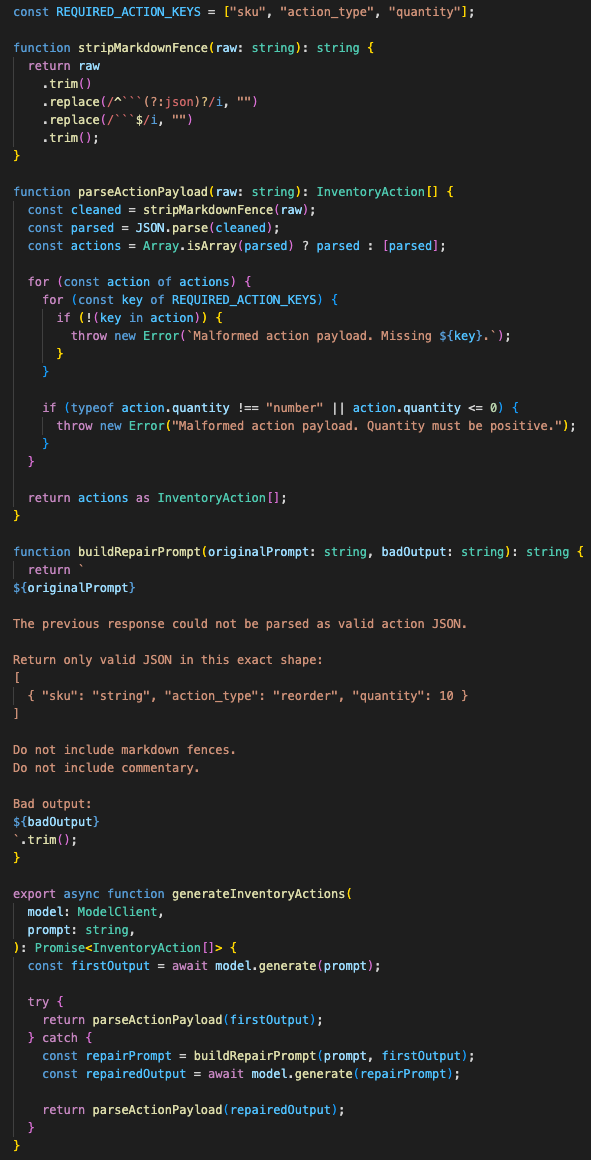
The gateway attempts one structured repair, then fails safely instead of looping through provider spend.
Streaming and polling solve different runtime problems
The gateway supports two response modes.
For faster interaction, it can stream directly from Together AI and return a text event stream to the frontend.
For heavier or slower work, it can return HTTP 202 Accepted, store job state, run the model call in the background through waitUntil, and let the frontend poll Redis for completion.
That solves two different user experience problems.
Streaming gives earlier output while the model is still generating.
Polling gives a fallback path for work that may outlive normal request timing.
The frontend handles both.
streaming response
→ read chunks
→ parse SSE lines
→ append content
202 response
→ poll /api/ai-gate?jobId=...
→ read job state
→ show completed result or failure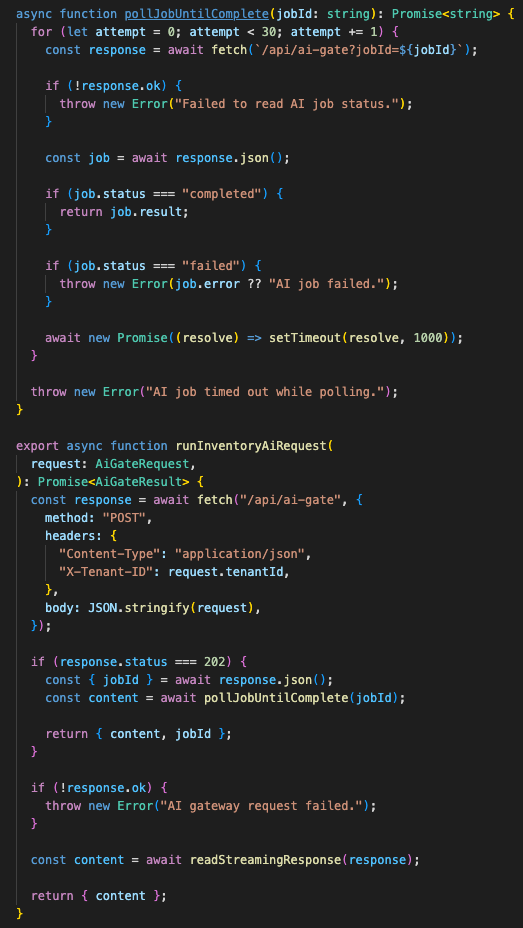
The frontend supports both streamed output and queued job polling so slower model work does not have to live inside one fragile request.
AI actions still go through the backend
The system still keeps action execution separate.
The model produces JSON.
The frontend parses it.
Then action execution calls a dedicated backend endpoint:
POST /api/v1/inventory/actionThat endpoint validates the action payload with Pydantic.
It fetches the tenant-scoped SKU.
It rejects quantities that exceed current stock for rebalance or shrinkage actions.
It recalculates status after the action.
Then it writes to the database.
That separation is the important part.
The model does not directly mutate inventory records.
It has to produce a structured action.
The backend applies the action through normal API rules.
For reorder, the backend increases stock and computes estimated financial impact.
For rebalance, it deducts stock and records the destination location.
For shrinkage or observational actions, it logs the action without pretending the model magically fixed the world.
There is still a risk here.
This is more agentic than the legal and medical systems.
It can update stock if the action path is executed.
So the safe framing is not “AI cannot write.”
The safer architecture is:
AI proposes.
The app parses.
The backend validates.
The system records.That is the right shape for this stage.
A production version would need more:
- Role-based permissions
- Approval queues
- Action audit logs
- Idempotency keys
- Rollback records
- Purchase order integration
- Warehouse location validation
- Supplier constraints
- Human approval thresholds based on cost
But the service boundary is already pointed in the right direction.
The system of record remains deterministic.
The AI gateway remains the reasoning layer.
The action endpoint remains the only mutation path for agent output.
That is much safer than giving the model database credentials and hoping it behaves.
Demo continuity is not production resilience
The frontend also has mock fallback data.
If the backend is unavailable, it can still run the demo locally with a realistic inventory set.
That is useful for portfolio demos, but it should be read honestly.
Mock fallback is not production resilience.
It is demo continuity.
The real production path is the backend database.
The data itself is shaped around the kind of businesses I see needing this.
Not giant enterprise ERP first.
Smaller operators with real inventory pressure:
- Stockouts
- Overstock
- Supplier lead times
- Manual imports
- SKU cleanup
- Cash tied up in slow-moving products
- Owners checking too many things by hand
Those businesses do not need a model to sound smart.
They need the system to show what should be ordered, what is overstocked, and what needs attention before the problem becomes expensive.
The useful architecture is the chain of constraints
- Inventory records stay in the backend
- Tenant isolation is enforced on every route
- Status is calculated server-side
- Insights are pre-computed without the model
- AI context is minified for cost control
- LLM calls go through a gateway
- Spend is pre-charged before inference
- Malformed JSON gets one retry
- Actions go through a typed backend endpoint
- Standard inventory work stays fast when AI is slow
The AI layer can make the product feel sharper.
It can analyze a SKU.
It can format an action.
It can summarize portfolio risk.
It can help an owner understand what to do next.
But it should never become the source of truth.
For inventory systems, the source of truth has to be boring.
SKU, stock, burn rate, lead time, cost, tenant, timestamp.
Everything else hangs off that.
Onto the next one. Let’s keep sharpening that edge!
First written on May 22, 2025.
Want to implement this architecture in your business?
Discuss Your Project