Building Retrieval-Augmented Generation Pipelines from Scratch
A contract retrieval pipeline produced a clean-looking answer from a broken half-clause. The fix was better ingestion: PDF cleanup, boundary-aware chunking, overlap, source metadata, and structured prompt assembly.
I’ve been testing document-heavy language model workflows lately. Mostly contracts, internal policies, and long PDF records where the model can’t just answer from memory and hope for the best.
GPT-4 is out now, but access is still limited. So for this build, I’m working with the available completion and chat APIs and designing the retrieval pipeline in a way that can move to stronger models once access opens up.
The failure mode is already clear.
If the retrieval layer gives the model a broken piece of text, the final answer still sounds clean.
That’s what happened here.
The language model cited a severed half-sentence as a major legal risk.
The system was supposed to answer questions over a small repository of vendor contracts. The first version had the usual shape:
PDF contracts
→ text extraction
→ chunking
→ embeddings
→ vector search
→ prompt assembly
→ model answer
The generation step was only as safe as the retrieved source text. Broken chunks still produced clean-looking answers.
People are starting to call this Retrieval-Augmented Generation. The name sounds new, but the backend shape is familiar enough: retrieve relevant material, pass it into a generation step, and make the answer depend on source text instead of model memory alone.
The part that broke was chunking
The part that broke was chunking.
A 200-page contract can’t fit into the prompt. The document has to be split into smaller pieces, embedded, and retrieved later when the user asks a question.
The first pass used fixed-size character chunks. Roughly 1,000 characters each. Easy to implement. Easy to store. Bad around legal language.
One liability clause got split across two chunks. The condition was in the first chunk. The penalty was in the second. When the user asked about contract risk, the vector search retrieved the penalty chunk without the condition.
So the model saw something real, but incomplete.
That’s the dangerous version of a bad answer. It doesn’t look fake from the outside. It quotes actual contract text. The problem is that the quoted text lost the surrounding logic that made it true.
Cleanup comes before embeddings
I stopped treating chunking as a text-size problem and moved it into the ingestion pipeline properly.
First, cleanup before embeddings.
Raw PDF extraction is messy. Headers, footers, page numbers, broken line wraps, duplicated section labels, weird whitespace. If those artifacts get embedded, they become searchable garbage.
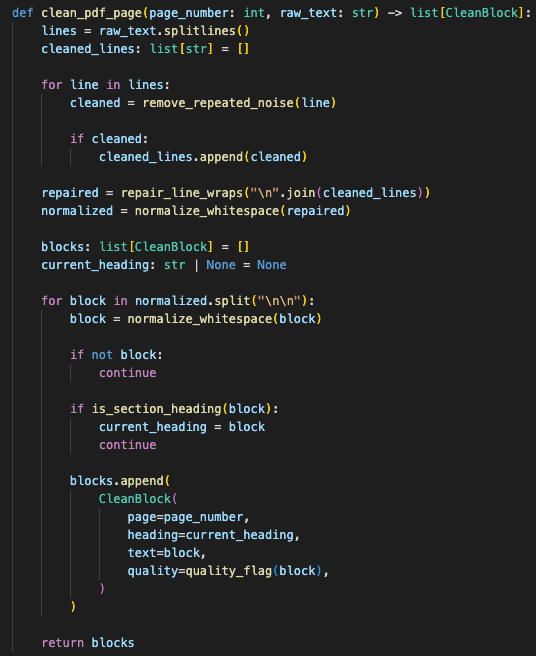
The cleanup step removed repeated document noise before embeddings turned that noise into searchable content.
The chunker needed document structure
Then I changed the chunking strategy.
The new chunker tries to split by meaning before it thinks about size:
- section heading
- paragraph
- sentence
- token budget
- overlap with neighboring chunks
The overlap matters. Legal and policy text often carries meaning across boundaries. A condition might sit at the end of one paragraph while the consequence starts in the next. Without overlap, retrieval can grab the consequence and drop the condition.
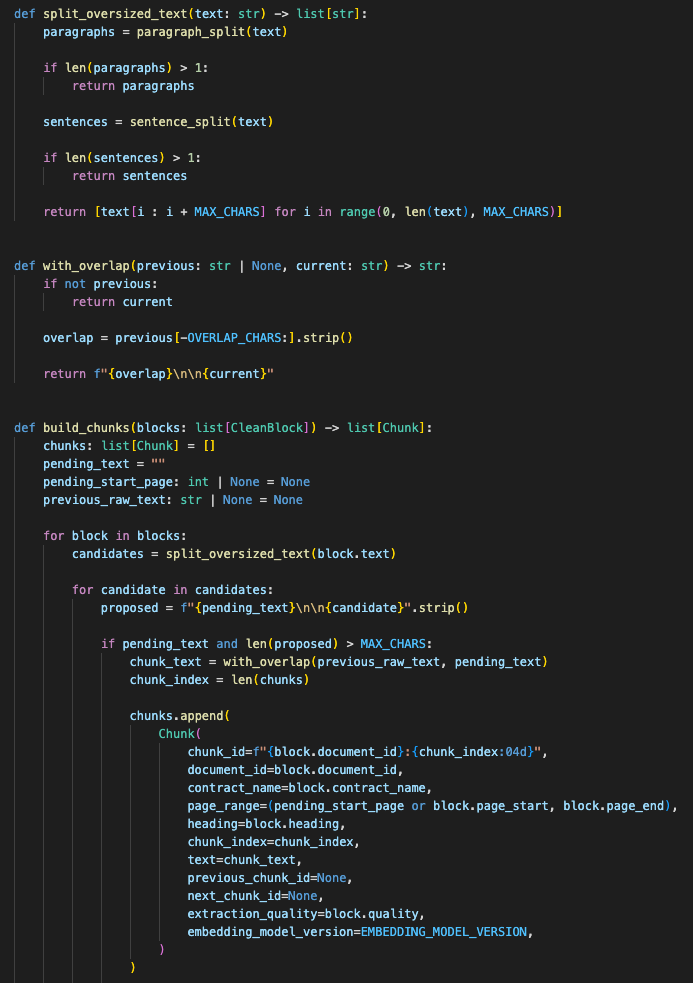
The chunker preferred structural boundaries first, then used overlap to preserve meaning across nearby clauses.
I also added metadata to every chunk. Not just the text.
Each stored chunk needed:
- document ID
- contract name
- page range
- section heading
- chunk index
- previous chunk ID
- next chunk ID
- extraction quality flag
- embedding model version
That made the pipeline easier to debug. When the answer looked wrong, I could inspect which chunks were retrieved and trace the failure back to extraction, chunking, ranking, or prompt assembly.
Prompt assembly needed source shape
The prompt assembly changed too. I stopped dumping retrieved paragraphs into the prompt as one loose blob. Each chunk went in with its source label and section boundary, so the model had a clearer idea of where one clause ended and another began.
A rough context block looked like this:
Source: Vendor Agreement A
Section: Limitation of Liability
Pages: 14-15
Chunk: 08
Text: ...
Source: Vendor Agreement A
Section: Limitation of Liability
Pages: 15-16
Chunk: 09
Text: ...That structure helps. The model receives text with source shape instead of a pile of similar-looking paragraphs.
Result
The system became more stable after that. It still needed inspection, and I wouldn’t trust it as a legal decision-maker. But the retrieval layer stopped handing the model isolated fragments as often.
This is where the engineering work is starting to show up with these systems.
The demo version is easy: upload PDF, embed chunks, ask questions.
The production version is less clean. You need extraction rules, chunk boundaries, overlap, metadata, source traceability, prompt formatting, and a way to inspect why a specific answer happened.
For contract workflows, a retrieved chunk has to carry enough meaning to be safely used. Similarity alone is too weak. The system has to preserve the surrounding structure that makes the text true.
Onto the next one. Let’s keep sharpening that edge.
First written on March 20, 2023.
Want to implement this architecture in your business?
Discuss Your Project