Centralizing Feature Logic for Real-Time Inference
A recommendation model looked strong offline and collapsed in production because training and serving computed the same feature differently. The fix was centralizing feature logic, serving versioned features through Redis, storing offline history in PostgreSQL, and enforcing freshness checks before inference.
The recommendation model looked strong in the notebook and collapsed the moment it touched production traffic.
Validation F1 was around 0.91. On the first production run, it dropped close to 0.45.
At first, nothing looked broken in the usual backend sense. The API was returning responses. PostgreSQL was writing records. The model server was reachable. Logs showed requests moving through the system.
The bad part was quieter than an outage.
The system was serving recommendations, but the recommendations were wrong.
We traced it back to one feature: user_engagement_score.
In training, that score came from a Pandas batch job over historical event logs. It counted page views, clicks, timing, recency, and a moving average over a bounded lookback window. The model learned from that version of user behavior.
For production, I had rewritten the same calculation in raw Python inside the FastAPI request path so the API could score users in real time.
That rewrite missed a small time-window rule.
The training job handled sparse recent activity one way. The FastAPI version handled it another way. Same feature name, different value.
That was enough to poison the model input.
The system had two realities
The old setup had two realities:
Training path:
historical events
→ Pandas feature job
→ training dataset
→ model trainingServing path:
live request
→ FastAPI recalculates engagement score
→ model inference
→ recommendation response
The feature name matched across training and serving, but the math did not.
This is where backend discipline matters in machine learning systems.
The model was not randomly bad. The API was feeding it a feature it had never really seen. The name matched. The math didn’t.
I didn’t want another patch inside the request handler. That would only create another place to forget a window rule later.
So I changed where the feature lived.
The feature calculation moved out of the request path
The feature calculation moved out of FastAPI and into a scheduled feature job. That job became the only place where user_engagement_score was computed.
The new shape was:
event logs
→ scheduled feature job
→ PostgreSQL offline feature table
→ Redis online feature cache
→ FastAPI reads feature vector
→ model inference
The scheduled job became the single source of truth for feature computation.
PostgreSQL held the offline feature history used for training:
user_id
feature_name
feature_value
feature_timestamp
feature_version
computed_atRedis held the latest online vector used for serving:
user_id → latest feature vector
Training needed history and reproducibility. Serving needed the latest feature vector fast.
That split kept the system practical.
Training needed history, timestamps, and reproducibility. Serving needed the latest value fast. The calculation stayed centralized, while the storage matched the access pattern.
The live API became a feature consumer
FastAPI stopped doing moving averages during the request. It validated the user ID, pulled the feature vector from Redis, checked the feature metadata, assembled the model input, and returned the recommendation.
The live path became:
request
→ validate user_id
→ fetch Redis feature vector
→ check version and freshness
→ assemble model input
→ run inference
→ return recommendation
The request path stopped recalculating features and started enforcing a versioned feature contract.
This made the product faster and safer at the same time.
The API no longer spent request time calculating historical windows. Redis lookup was around two milliseconds for the feature vector. More importantly, training and serving were now reading from the same feature definition.
Freshness became part of correctness
The edge case was stale correctness.
A cached feature can be mathematically consistent and still too old to trust. If the nightly job failed, Redis might still have yesterday’s value and the API would look healthy while the recommendation quality decayed.
So the API checked three things before using the vector:
feature exists
feature version matches the model
computed_at is inside the freshness windowIf any of those failed, the request used a fallback recommendation and logged the reason.
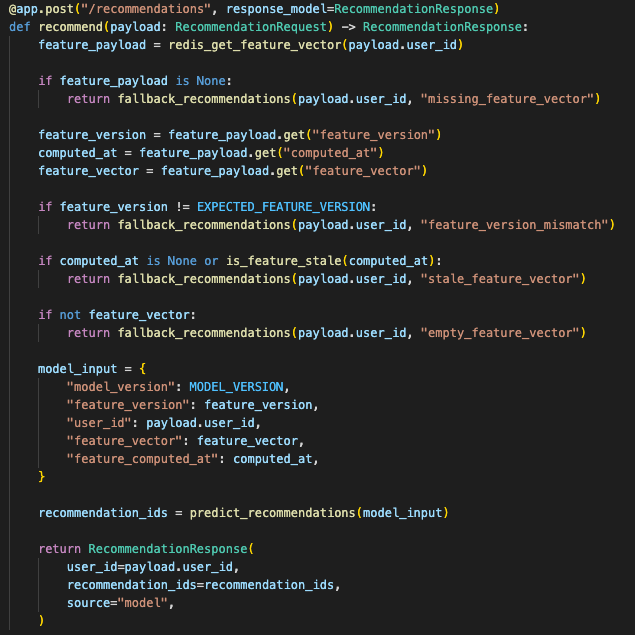
The inference path rejected missing, stale, or wrong-version feature vectors before calling the model.
The version check was non-negotiable.
If the model was trained on user_engagement_score:v3, production had to serve v3. A Redis key holding v2 under the same user ID would recreate the same silent failure with cleaner infrastructure.
The model input contract carried the metadata:
model_version
feature_version
user_id
feature_vector
feature_computed_at
The model input carried enough metadata to debug wrong recommendations without reading two implementations line by line.
That gave me a real debugging surface. When recommendations looked wrong, I could inspect the model version, feature version, freshness window, and Redis hit behavior instead of reading two separate implementations line by line.
The final setup was not a big feature platform. It was a small backend correction with a large effect:
- one scheduled feature job
- PostgreSQL for offline feature history
- Redis for online feature serving
- feature versioning
- freshness checks
- fallback recommendations
- inference logs with model and feature metadata

The backend centralized feature logic, stored it for both access patterns, and made inference depend on a versioned contract.
Result
This build made the failure obvious in hindsight.
I had put data science logic inside the live API because it felt faster to ship. Then the API became a second source of truth. Once that happened, the model quality depended on two code paths staying mathematically identical.
That is not a safe dependency.
The better backend move was to centralize the feature, store it for the two access patterns, and make the request path read from a versioned contract.
The model improved because the backend stopped lying to it.
Onto the next one. Let’s keep sharpening that edge.
First written on December 10, 2020.
Want to implement this architecture in your business?
Discuss Your Project