Cold Starts and Kubernetes: Managing Latency in Burst Traffic
A model-backed API dropped requests during a burst even while Kubernetes was scaling. The fix was making model readiness explicit, blocking traffic from cold pods, adding ingress rate limits, and treating autoscaling as delayed capacity instead of instant rescue.
How’s everyone doing?
I hope everyone’s keeping safe. Strange times right now. Work is still moving, but everything feels heavier with the COVID-19 pandemic unfolding in the background.
Anyway, let’s get started.
Today, I’m writing about a backend failure that looked like an autoscaling problem at first.
The API dropped a large batch of requests in a few minutes. That was the issue.
I had recently moved a model-backed pipeline into Kubernetes. The goal was resource control: keep enough pods running for normal traffic, then let the cluster add capacity when demand spikes.
Traffic increases. CPU increases. Kubernetes adds pods. More workers handle the load.
The actual system had a rougher shape:
client batch job
→ API gateway
→ Kubernetes ingress
→ active model pods
→ autoscaler notices CPU spike
→ new pods start
→ model loads into memory
→ pods become ready
The autoscaler created more pods, but the new pods still had to pull images, boot the app, and load the model before they were useful.
The burst arrived faster than useful capacity
My first failure was the traffic pattern.
A downstream batch job dumped a large backlog of text payloads into the API at once. No pacing. No streaming. No backpressure. Just a wall of requests.
The active pods started taking the hit. CPU climbed. The Horizontal Pod Autoscaler reacted and requested more capacity.
That part worked.
The problem was what happened next.
The new pods did not become useful immediately.
A normal web container can start fast. A model-serving container is heavier. It has to pull the image, start the app, load the model, warm the runtime, and only then accept real traffic.
That delay was the cold start penalty.

The pod existed before it could serve inference. That gap mattered during the burst.
The system needed more workers right away, but the new workers needed time before they could actually run inference. During that window, requests kept arriving. Some connections waited. Some timed out. The load balancer started returning gateway errors.
The cluster was technically scaling, but the product was still failing.
That is the annoying part of autoscaling model workloads. Scheduling more pods does not mean the system has more useful inference capacity yet.
There is a difference between a pod being created and a pod being ready.
That difference has to be made explicit.
Readiness had to mean model-loaded
My first fix was around readiness.
I added proper startup and readiness checks inside the FastAPI service. Kubernetes needed a reliable way to ask:
“Can this pod actually serve a request now?”
The answer should only be yes after the model is fully loaded and available in memory.
The app needed routes like this:
/health/live
/health/ready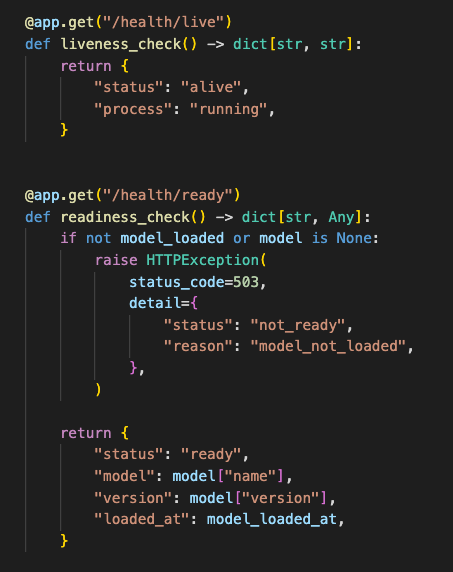
Liveness proved the app process was alive. Readiness proved the model was loaded and inference could run.
The distinction mattered.
A liveness check tells Kubernetes the process is alive.
A readiness check tells Kubernetes the pod can receive traffic.
Those are different for model-serving systems.
Before this, a pod could look alive while still loading the model. That made the ingress layer too optimistic. It could send work to a container that was running but not ready.
After the readiness check, the pod had to prove the model was loaded before receiving payloads.
pod starts
→ app boots
→ model loading begins
→ readiness stays false
→ model loaded
→ readiness returns 200
→ ingress can route traffic
Ingress only routed traffic to pods that had passed a model-loaded readiness check.
That fixed the routing problem but it did not fix the burst problem by itself.
The ingress became the shock absorber
The second fix was the traffic funnel.
If a client dumps too much work at once, Kubernetes cannot bend time. New pods still need time to start. Model weights still need to load. Disk and memory still have physical limits.
So the gateway needed to absorb some of the shock.
I added stricter rate limiting at the ingress layer. The goal was simple: stop one bad batch job from flooding the model workers faster than the cluster could react.
incoming burst
→ ingress rate limit
→ controlled request flow
→ active pods continue serving
→ new pods warm up
→ traffic expands gradually
Rate limiting smoothed the request flow while new model pods warmed up behind readiness checks.
This is where the backend boundary mattered again.
The API should not be forced to eat every request at the exact speed a client sends it. If the client has no pacing, the server needs a pacing layer.
Rate limiting was not about punishing the client. It was about protecting the system from a traffic shape it could not safely absorb.
For this setup, I wanted three things:
- do not route traffic to cold pods
- do not let one batch job flood active workers
- do not pretend autoscaling is instant
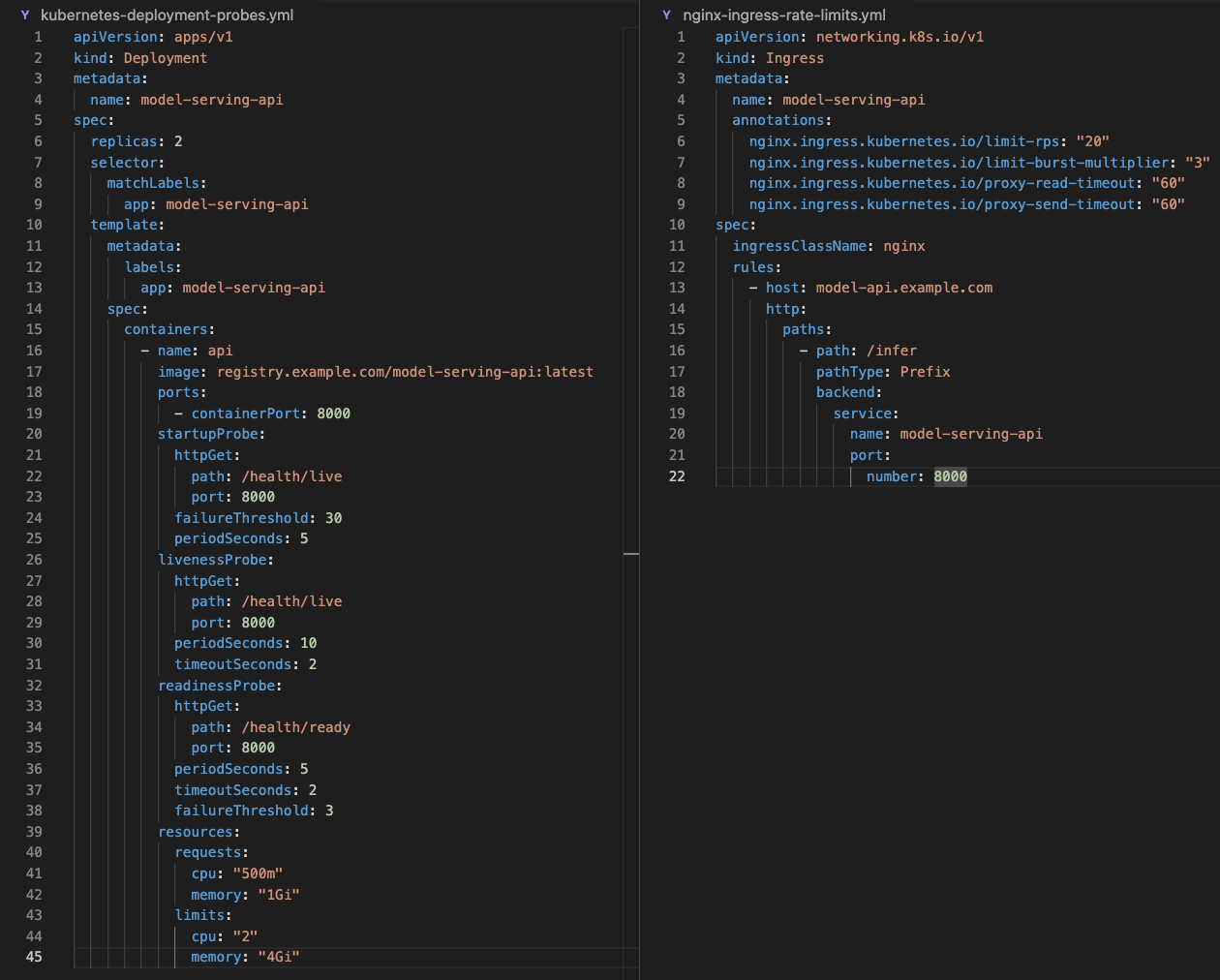
The deployment tied readiness to model-loaded state and throttled bursts before they reached the workers.
The model load sequence became part of the contract
The model load sequence also became part of the backend contract.
A model-serving pod was not ready when Python started. It was ready when the model was loaded, the inference function could run, and the readiness endpoint said yes.
Small distinction. Big difference under pressure.
Before:
pod exists
→ ingress may send traffic
→ model still loading
→ request hangs
→ timeoutAfter:
pod exists
→ model loads
→ readiness passes
→ ingress sends traffic
→ request has a real worker
Readiness changed the routing layer from optimistic to accurate.
The edge case was a short traffic spike.
If the burst lasts only a minute, new pods may come online after the worst part is already over. That does not mean autoscaling failed. It means autoscaling reacted slower than the traffic arrived.
For model-serving systems, that is normal. Cold starts are not free.
So the system needed to reduce the blast radius of sudden traffic instead of assuming scale-out would save every request instantly.
The final shape became more stable:
client
→ ingress rate limit
→ ready-only routing
→ active model pods
→ HPA scales new pods
→ new pods load model
→ readiness opens traffic
The final path combined rate limiting, ready-only routing, active model pods, HPA scale-out, and readiness-gated warmup.
Result
This build reminded me that Kubernetes does not understand machine learning workloads by default. It schedules containers.
It does not know that a pod still needs to load a heavy model into memory. It does not know that a batch job is reckless. It does not know that a pod can be alive and useless for inference at the same time.
I had to teach the system those boundaries.
For me, the useful pieces were simple:
- startup checks
- readiness checks
- model-loaded state
- ingress rate limits
- controlled request flow
- autoscaling with realistic expectations
The API stopped routing traffic to cold pods. Burst traffic had a throttle. New workers had time to warm up. The system still had limits, but the failure mode became cleaner.
A model-serving cluster is only useful when the routing layer respects model startup time.
Otherwise, autoscaling becomes theater.
Onto the next one. Let’s keep sharpening that edge.
First written on March 11, 2020.
Want to implement this architecture in your business?
Discuss Your Project