Defending Backend Systems Against Probabilistic Model Outputs
A legal extraction prototype broke when the model returned helpful prose instead of JSON. The fix was a defensive backend wrapper with raw response capture, parsing cleanup, strict schemas, source evidence checks, capped retries, a dead letter queue, and human review.
The downstream database crashed because the model returned a polite paragraph instead of a JSON object.
I was working on an automated extraction prototype for unstructured legal contracts.
The goal was simple on paper:
contract text in
structured extraction outI wanted the system to identify clauses, pull key terms, preserve the source text, and store the result in a database for review.
The first few tests were impressive.
The model identified a liability clause correctly. It summarized a governing law section cleanly. It found renewal language that would have taken a person a few minutes to locate manually.
Then it hallucinated a termination fee that did not exist in the contract.
After that, it ignored the requested JSON format and returned a bulleted explanation.
That one broke the backend.
The pipeline expected a structured object. The model returned:
“Here are the clauses I found…”
Then a polite list.
No stable keys.
No valid JSON.
No predictable shape.
Just helpful-looking prose.
The original architecture was too trusting:
contract text
→ model prompt
→ expected JSON response
→ parser
→ PostgreSQL write
→ review dashboard
The first version treated generated text like a stable API response with a dependable object shape.
That looked normal because I had treated the model like a standard API.
That was the mistake.
A model response is not a normal API contract
A normal API has a contract. You send a request. You expect a documented response shape. If the response is invalid, it usually fails in a boring way.
A language model behaves differently.
It can follow the requested format once, drift on the next run, add commentary, invent missing details, or return a valid-looking answer that is still wrong.
The failure mode is strange because the output often sounds reasonable.
That makes it dangerous inside a backend pipeline.
Broken JSON is obvious.
Confident fiction is harder.
I stopped raw model output from touching the database
The first fix was to stop letting raw model output touch the database.
I added a wrapper around the model call.
The wrapper became the real integration boundary:
contract text
→ prompt builder
→ model request
→ raw response capture
→ cleanup parser
→ schema validation
→ evidence check
→ retry path
→ dead letter queue
→ database write only after validation
The wrapper separated probable text from database writes and made validation the real system boundary.
Few-shot prompting reduced drift, but did not remove it
The prompt needed structure.
Open-ended instructions were too loose for extraction. Asking the model to “analyze this contract” produced analysis. I needed records.
So I moved to few-shot prompting.
The prompt included several examples of contract text and the exact JSON output I wanted back.
The examples were intentionally boring:
input clause text
expected JSON
input clause text
expected JSON
input clause text
expected JSON
actual contract text
model completes the next object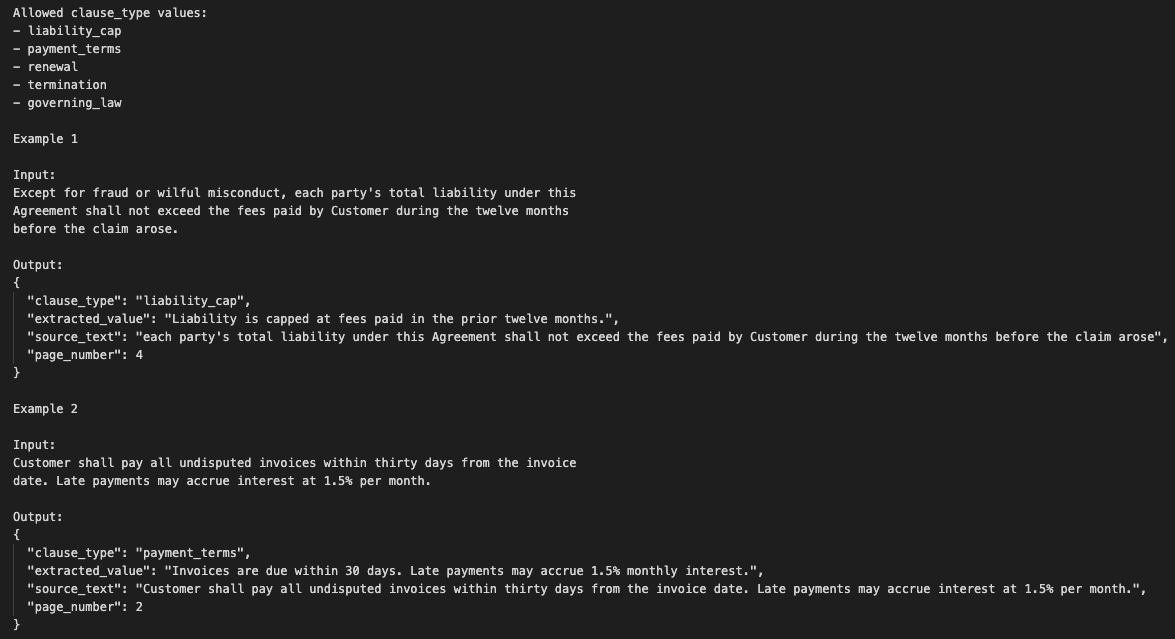
The prompt pressured the model toward records instead of commentary, but it did not make the output safe by itself.
This helped.
It did not solve the problem.
The model still added filler around the JSON. Sometimes it changed key names. Sometimes it returned a list instead of an object. Sometimes it included values that were not supported by the source text.
So the backend needed a hard rejection layer.
The parser treated model text as hostile input
The raw response went through a parser first:
raw model text
→ extract JSON block
→ strip conversational filler
→ parse JSON
→ validate schema
→ reject or continue
The parser accepted only clean structured objects and rejected prose, filler, malformed JSON, and unexpected shapes.
The schema was strict.
Each extraction needed enough metadata to be traceable:
document_id
clause_type
extracted_value
source_text
page_number
model_version
prompt_version
validation_status
created_at
Every stored extraction had to carry source evidence, document location, model version, prompt version, and validation status.
The source_text field mattered most.
If the model claimed there was a termination fee, it had to provide the exact text from the contract that supported the claim.
No source text, no write.
That one rule caught a lot of garbage.
Missing key? Reject.
Wrong type? Reject.
Unsupported clause type? Reject.
Empty source text? Reject.
Invented value without supporting language? Reject.
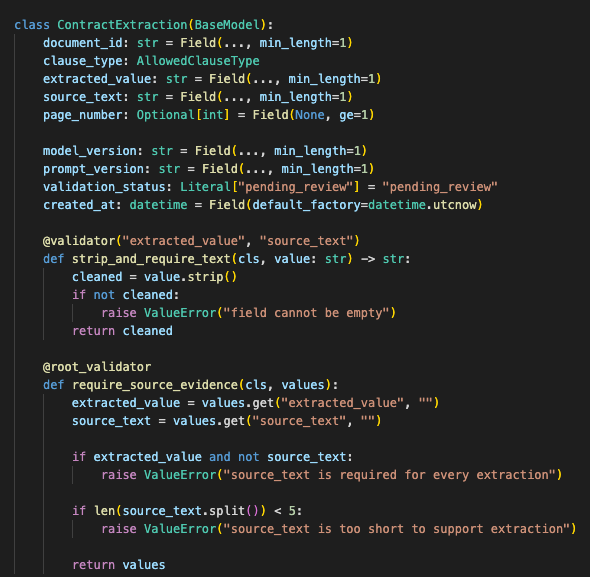
The schema enforced allowed clause types, required source text, model metadata, prompt metadata, and strict field rules.
Retries were capped and failures became reviewable data
Validation failures went into a controlled retry path.
The retry did not run forever. I capped it.
First attempt: normal extraction prompt.
Second attempt: lower temperature and stricter JSON-only instruction.
Third attempt: repair prompt using the validation error.
After that, the record went into a dead letter queue.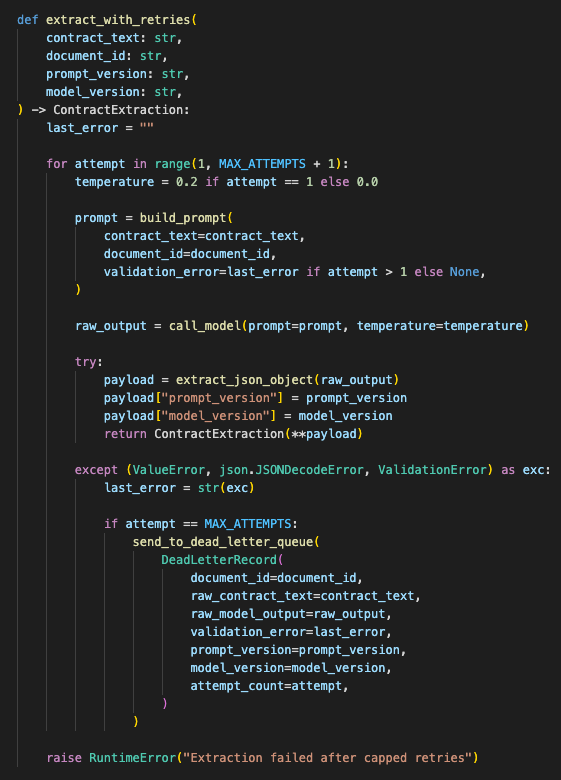
The retry path tried repair once or twice, then stopped and preserved the failed payload for review.
The dead letter record stored:
document_id
raw_contract_text
raw_model_output
validation_error
prompt_version
model_version
attempt_count
created_at
The dead letter queue turned failed model outputs into a dataset for improving prompts, parsers, and validation rules.
That queue was useful.
It showed which clauses caused format drift. It showed which prompt examples were weak. It gave me real failed outputs to improve the wrapper instead of guessing from scattered logs.
Valid JSON can still be false
The edge case that forced the most caution was valid JSON with false content.
Example:
{
"clause_type": "termination_fee",
"extracted_value": "$50,000",
"source_text": "Either party may terminate this agreement with 30 days written notice.",
"confidence": 0.91
}The JSON parses.
The schema passes.
The extracted value is still false.
That is where normal backend validation runs out.
Type checks can prove the shape is valid. They cannot prove the legal claim is true.
So the system had to preserve evidence and route the output through review.
The review UI showed the model’s extracted value beside the exact source text and document location.
extracted value
source text
document location
model version
prompt version
validation status
The review screen made model claims inspectable against source evidence before they became approved records.
That changed the role of the model.
It was allowed to propose structure.
It was not allowed to become the source of truth.
The database stored approved records, not raw model guesses.
The final backend shape became:
contract upload
→ text extraction
→ few-shot prompt builder
→ model call
→ raw response logging
→ cleanup parser
→ schema validation
→ source evidence check
→ capped retry path
→ dead letter queue
→ human review
→ approved database record
The model proposed extraction records. The backend decided what could become stored data.
Result
The useful lesson was uncomfortable:
The model made extraction feel easy before the system was actually safe.
A demo can survive a polite paragraph.
A backend pipeline cannot.
The fix was boring:
- few-shot prompt templates
- raw response capture
- JSON cleanup
- strict schema validation
- source text requirements
- prompt versioning
- model versioning
- capped retries
- dead letter queue
- human review path
Those pieces turned model output into something the rest of the software could handle.
The model could read and draft structure.
The backend had to decide what was allowed to become data.
Onto the next one. Let’s keep sharpening that edge.
First written on November 18, 2021.
Want to implement this architecture in your business?
Discuss Your Project