Designing a Multimodal Routing Layer Before Vision Access
A JPEG broke the old text-only chat assumption before any vision model was involved. The fix was a multimodal request envelope, file validation, route classification, and provider-agnostic capability routing.
Gemini is everywhere this week.
The bigger shift is pretty obvious now. Users are going to stop sending only text.
They’re going to drop screenshots, charts, receipts, diagrams, PDFs, product photos, support logs, and messy combinations of all of them into the same chat box.
The old assumption was simple:
user message = stringThat assumption is starting to break.
The first failure in my own interface came from a JPEG.
A user uploaded a screenshot of a flowchart. The frontend treated it like another chat message and pushed the payload forward. The backend expected text. The parser tried to handle the image path like a string input and failed before any model call happened.
No external vision model was involved yet. The request schema was already wrong.
The old flow only worked for text
The old flow looked like this:
client sends message
→ API validates text
→ prompt gets assembled
→ text model receives prompt
→ response returnsThat flow works when every input is text. It becomes fragile once the chat box accepts files.
So I started changing the API boundary before wiring in any live vision endpoint.
The message became an envelope
The new shape treats a chat message as an envelope:
message
session_id
user_text
content_parts[]
- text
- image_reference
- document_reference
- mime_type
- size
- upload_id
The API boundary validates the content envelope before any model provider receives the request.
That changed the backend responsibility.
The API gateway now inspects the request before deciding what kind of work it is. Plain text stays on the normal text path. Images go through file validation and storage first. Unsupported files are rejected before they reach any model layer.
For now, the router only needs to classify the request:
incoming request
→ validate session
→ inspect content parts
→ text only: normal text route
→ image included: store and mark as vision-required
→ unsupported file: reject
→ response: accepted, rejected, or queued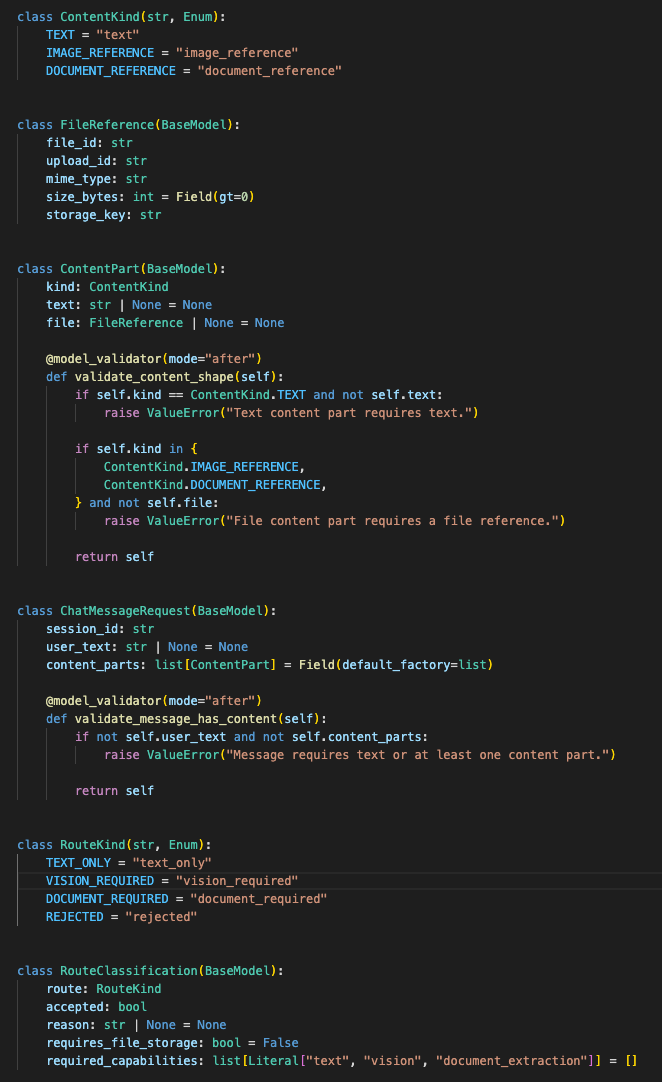
The request schema separates user text from file references so routing does not depend on treating every input as a string.
Base64 is not the default boundary
The biggest change is avoiding base64 blobs as casual JSON.
Base64 looks convenient in a prototype. It gets ugly fast. Large payloads hit request limits, inflate logs, increase memory pressure, and make retries heavier than they need to be. A chat API should not pass a screenshot around like a normal text field.
The cleaner path is:
image upload
→ object storage
→ file record created
→ chat message references file ID
→ backend validates ownership and MIME type
→ router marks request for vision-capable modelThat keeps the message small and gives the backend a real file boundary.
Validation comes before model routing
The validation layer has to exist before model routing:
- allowed MIME types
- max file size
- image decode check
- session ownership
- upload expiry
- file scan status
- safe logging
- route classification
- clear rejection reason
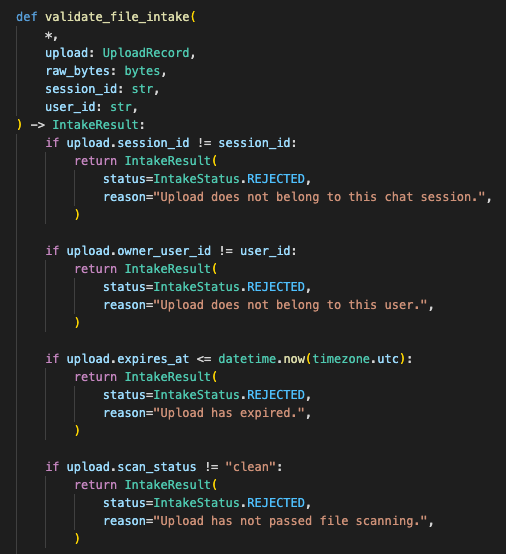
The file validator normalizes uploads into safe references before the chat router decides which model capability is needed.
Provider choice stays behind the router
This also keeps provider choice from leaking into the whole app.
The route table can stay simple:
text only
→ text model
text + image
→ vision-capable model
document upload
→ extraction pipeline
→ retrieval or summarization route
unsupported file
→ reject earlyThe model names can change. Gemini, GPT-4 with vision access, Claude, local vision models, whatever comes next. The backend should classify the work first, then select the model based on capability, cost, latency, and availability.

The router matches requests to capabilities first, then selects providers based on availability, cost, and latency.
Cost control starts at classification
This is also where cost control starts.
A plain text question should not accidentally take the expensive vision path. An image upload should not crash the text parser. A malformed file should not reach the model provider. A provider outage should not corrupt the chat session.
Multimodal AI makes the interface feel simpler. The user drops whatever they have into the box.
The backend has to get stricter because of that.
A chat system now needs content envelopes, upload storage, file validation, route classification, capability matching, and fallback behavior. The model endpoint is only one piece. The real work starts at the API boundary where the system decides what the user actually sent.
Onto the next one. Let’s keep sharpening that edge.
First written on December 15, 2023.
Want to implement this architecture in your business?
Discuss Your Project