Dynamic Batching for Heavy PyTorch Workloads
A BERT classification API had a GPU but still timed out because it fed the model one request at a time. The fix was moving from a custom Python batching queue to TorchServe dynamic batching with per-item validation, request mapping, and serving metrics.
The API timed out under a traffic spike that should have been manageable.
I was running a BERT text classification model on an AWS g4dn.xlarge. The instance had a GPU, but the request path was feeding the model one text payload at a time. Every HTTP request triggered its own tokenization step, tensor move, forward pass, and response.
The flow looked like this:
HTTP request
→ tokenize text
→ move tensor to GPU
→ run BERT
→ return class label
The serving code was simple, but each request paid its own tokenization, tensor transfer, and forward-pass cost.
The serving code was simple, but the workload shape was wrong. BERT is not cheap to run, and sending one short text input per forward pass left too much GPU capacity unused while the API workers queued requests.
The first fix was a custom batching queue
The first fix I tried was a custom Python batching queue.
Incoming requests went into memory. A background thread waited around 50 ms, collected pending items, tokenized them together, ran one batched inference pass, then split the results back to each caller.
incoming requests
→ in-memory queue
→ short wait window
→ batch tokenization
→ one BERT forward pass
→ split responses
A short batching window improved throughput by feeding the GPU work in a better shape.
Throughput improved, but the queue became part of the serving infrastructure. I had to manage request IDs, futures, timeouts, malformed inputs, cancelled requests, partial failures, and response routing inside the application layer.
The worst failure was batch poisoning.
One malformed string could fail tokenization for the batch. That meant several unrelated users could receive a 500 because one input was bad. I added validation before enqueueing and kept request IDs attached to each item, but the custom loop kept growing.
At that point, the serving path looked like this:
request arrives
→ validate text
→ assign request ID
→ enqueue future
→ batching thread waits
→ tokenize batch
→ run inference
→ split outputs
→ resolve responses
→ clean up timeouts and failed items
The custom queue proved the batching idea, then became too much serving infrastructure inside the application layer.
TorchServe became the serving boundary
I moved the model into TorchServe.
The new path was smaller:
client request
→ API layer
→ TorchServe endpoint
→ custom BERT handler
→ batched inference
→ response
The application layer returned to product concerns while the inference server owned batching, workers, model loading, and serving metrics.
TorchServe let me configure batching with batch_size and max_batch_delay. The handler still had to do the application-specific work: validate text, cap sequence length, tokenize inputs, preserve request mapping, and return per-item errors.
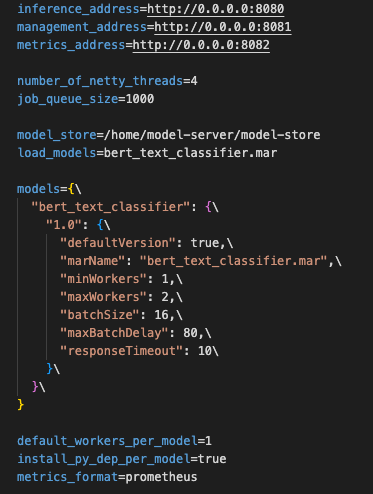
The serving config controlled batching delay, batch size, workers, and handler wiring.
The key rule was simple:
Bad input fails before batch construction.
Empty text, oversized payloads, invalid encodings, and missing fields were rejected per request. Valid requests could still be batched together without one bad input taking down the group.
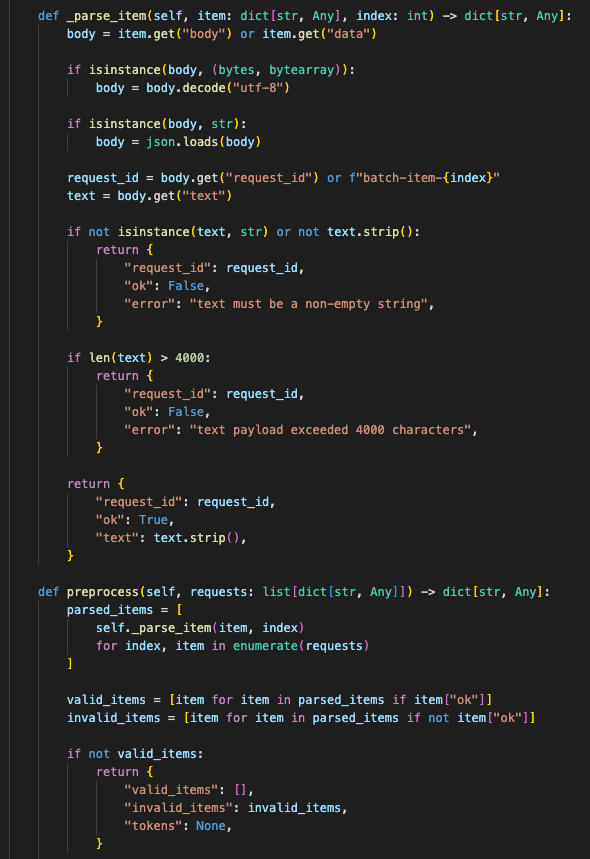
The handler validated each item before batch construction, preserved request IDs, and returned per-item errors instead of poisoning the batch.
The tuning was practical
After migration, the endpoint moved from roughly 15 requests per second to around 120 requests per second under the same class of traffic. The batching window settled around 80 ms for this workload, which was acceptable for the classification flow.
The tuning was mostly practical:
larger batch_size
→ better GPU use
→ higher memory pressure
larger max_batch_delay
→ more complete batches
→ slower individual response
smaller max_batch_delay
→ faster response
→ weaker batching under uneven traffic
Dynamic batching increased throughput and GPU utilization while keeping latency acceptable for classification.
The final setup was:
- BERT packaged for TorchServe
- custom handler for preprocessing
- input validation before tokenization
- sequence length caps
- dynamic batching
- per-item error handling
- serving metrics watched under burst traffic

The final serving boundary handled batching, validation, request mapping, GPU inference, and metrics without custom queue logic inside the API.
Result
The useful lesson from this build:
The expensive part was already paid for. The GPU was there. The waste came from feeding it work in the wrong shape.
The custom queue proved the batching idea, then became the thing to remove.
TorchServe gave the model a better serving boundary. The application layer went back to handling product concerns. The inference server handled batching, workers, model loading, and serving metrics.
For this workload, the win was straightforward:
batch size 1
→ low throughput and request backlog
dynamic batching
→ higher throughput, cleaner failure handling, better GPU useOnto the next one. Let’s keep sharpening that edge.
First written on September 28, 2020.
Want to implement this architecture in your business?
Discuss Your Project