Financial Intelligence: Keeping AI Away From the Ledger
Clearworth keeps the financial ledger under deterministic backend control while using AI for language, routing, and structured action proposals. The model can explain and propose, but money records still move through typed schemas, guarded mutations, and normal database rules.
The dangerous part was letting the model touch the ledger.
This started as a private build for someone in my network who wanted a personal finance workflow they could own. The goal was not to beat every App Store budgeting app on feature count. The goal was to streamline their own finance routine, keep the ledger controllable, and test what a personalized AI assistant could do when it had access to structured records.
That changed the cost model.
A subscription app hides infrastructure cost inside the subscription and keeps the workflow inside its own product rules. This build exposed the cost directly: hosted frontend, backend service, model calls, storage, and maintenance.
That was acceptable for this use case because the point was control, customization, and learning what a private AI finance assistant could safely handle.
So I treated hosting and model usage as part of the architecture, not an afterthought.
A Vercel frontend, Railway backend, and Together AI calls are cheap at low volume, but they are still real operating costs. The system needed hard boundaries around provider calls, request loops, and accidental usage spikes.
That is why the LLM gateway had a spend cap, Redis-backed usage tracking with memory fallback, provider timeouts, and a concurrency limit. If the assistant became expensive or unstable, the backend had to fail before the bill became the failure.
The model handles language. The backend handles money.
The first version of the architecture made the service boundary explicit:
browser UI
→ local IndexedDB storage
→ API service layer
→ FastAPI backend
→ Pydantic validation
→ SQLAlchemy models
→ deterministic finance services
→ LLM gateway for language and action routing
The ledger stays behind the backend. The model sits beside the finance services, not inside the database path.
I called the project Clearworth for the client, mostly to give the system a clean name while building it. The important part was the architecture.
The model handled language.
The backend handled money.
That rule shaped the whole system.
The ledger starts as structured data
The FastAPI backend owns the financial records through SQLAlchemy models. The core table is a financial log with indexed fields for type, amount, date, expense category, and income category. Monthly goals, budgets, balances, performance metrics, and system metrics sit beside it as separate tables.
That shape matters because the assistant can only be useful if the ledger is structured first.
FinancialLog
* logType
* description
* amount
* currency
* date
* expenseCategory
* incomeCategory
* expectedSavings
* createdAt
* updatedAt
MonthlySavingsGoal
* month
* projected_amount
* actual_amount
MonthlyBudget
* month
* category
* projected_amount
* day_of_month
MonthlyBalance
* month
* balance_type
* account_type
* amount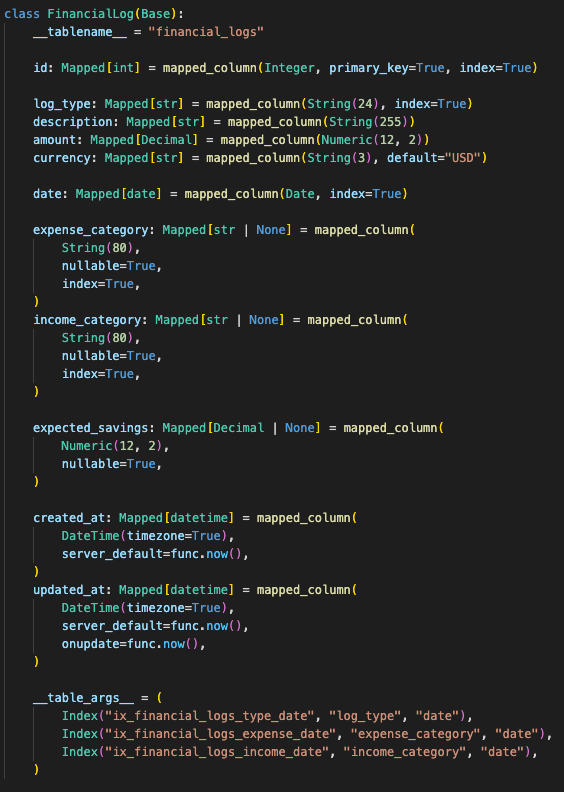
The finance assistant sits on top of structured records. It does not replace them.
The finance assistant sits on top of that structure.
It doesn’t replace it.
Questions stream. Mutations go through JSON mode.
The agent endpoint has two paths.
Normal questions stream back as text.
Mutation requests go through strict JSON mode.
That split became the main safety boundary.
For a normal question, the backend builds a compact context packet. It does not dump the entire database into the model. If the user asks for a summary, the backend calculates the monthly income, expenses, net flow, savings rate, and goal progress in Python first.
The model receives the result as context.
It explains numbers that already exist.
It does not calculate them.
That was the right tradeoff because LLMs can sound confident while doing bad arithmetic. In finance, a wrong total is not a harmless hallucination. It changes the user’s trust in the whole system.
The summary path uses date ranges instead of database-specific month functions. That was deliberate. SQLite and Postgres handle date formatting differently. I wanted the backend to work locally and on Railway without fragile SQL dialect assumptions.
The flow became:
summary trigger
→ query current month by date range
→ aggregate income and expenses through SQLAlchemy
→ calculate net flow in Python
→ calculate savings rate in Python
→ pass compact summary to the model
→ stream explanation to the UI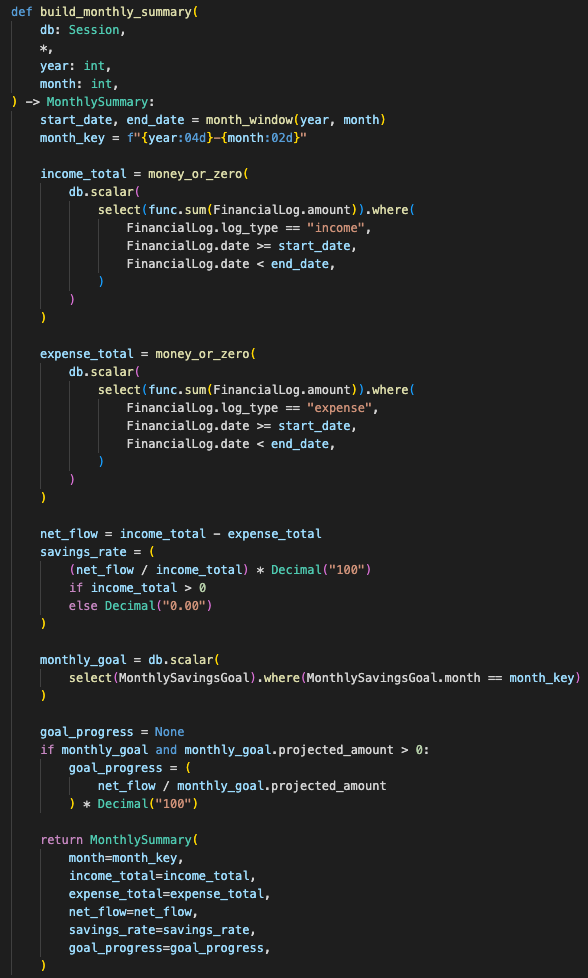
The backend calculates income, expenses, net flow, and savings rate before the assistant explains the result.
Database writes need stricter handling
The mutation path is stricter.
If the user says “delete the transaction from Jan 18” or “change that lunch to $20,” the request does not go straight from model output to database write.
It goes through intent detection first.
add
create
delete
remove
update
edit
change
modify
recordThose words push the request into the mutation path. The backend switches the model into JSON mode and asks for a structured action.
The expected shape is not prose. It is an action object.
action_type
entity
summary
payloadThen the backend validates the action before execution.
For updates and deletes, the backend tries to resolve the target through an exact ID first. If there is no ID, it can fall back to date or description. If fuzzy description matching finds more than one record, it refuses to bulk delete and asks for a more specific target.
That guardrail is small, but important.
A personal finance assistant should not delete five transactions because the word “coffee” matched too many rows.
The mutation flow looks like this:
user request
→ mutation intent detected
→ LLM forced into JSON mode
→ action parsed and normalized
→ Pydantic action schema validates shape
→ backend resolves target record
→ SQLAlchemy executes write
→ commit or rollback
→ UI receives refresh action
The assistant can structure an action. The backend decides whether that action is safe enough to run.
This is where the system started feeling less like an AI demo and more like a backend application with an AI interface.
The assistant can suggest or structure the action.
The backend decides whether that action is safe enough to run.
There is also a separate path for normal assistant replies. Those use Server-Sent Events so the UI can start receiving text before the full response finishes. That matters for perceived latency. Finance questions often involve summaries and explanations, and waiting for one large response makes the app feel heavier than it is.
So the agent has two runtime modes:
analysis/chat
→ streaming response
→ no database mutation
mutation/tooling
→ synchronous JSON
→ validated database writeThe same endpoint supports both, but the execution model changes based on risk.
The LLM gateway has cost and runtime controls
The LLM gateway has its own controls.
Together AI sits behind a small backend client instead of being called directly from the frontend. That gave me one place to enforce provider timeouts, concurrency limits, model routing, and budget controls.
The gateway checks spend before requests. It uses Redis if available and falls back to in-memory tracking if Redis is not configured. It also uses a semaphore to cap concurrent provider calls, and a 30-second timeout so requests do not hang forever.
The basic control loop is:
check budget
→ acquire concurrency slot
→ call Together AI
→ track token usage
→ update spend counter
→ return response or controlled error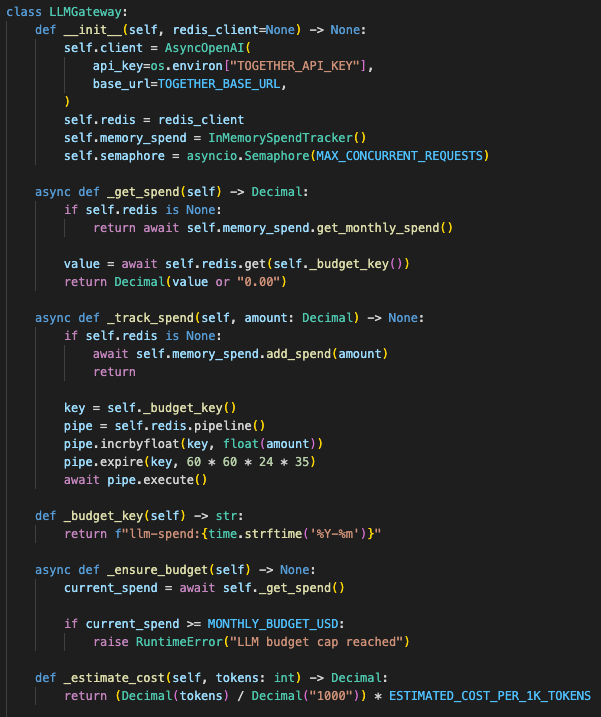
The gateway keeps model spend, timeouts, streaming, and concurrency outside the frontend.
This mattered because public demos and private tools can both get abused in boring ways. Duplicate requests, accidental loops, impatient double-clicks, and reload storms can burn API calls without adding user value.
The agent endpoint adds another guardrail before the LLM gateway. It hashes the prompt and rejects exact duplicates sent within two seconds from the same session.
That is not sophisticated distributed rate limiting. It is a practical safety mechanism.
The backend also keeps short in-memory conversation history with a session TTL. It trims the context window to avoid dragging old conversation state into every call. The README is honest about this being single-instance behavior. If the system needed multi-worker or serverless scale, that state should move to Redis.
For this stage, Railway runs the backend as one worker. SQLite is used for plug-and-play deployment and demo seeding. The deployment starts by seeding data, then runs Uvicorn. That is fine for a controlled reference app. It is not pretending to be a multi-tenant banking platform.
That distinction matters.
A good engineering log should say where the system is strong and where it is intentionally scoped.
Local-first storage keeps the UI responsive
The local-first side is handled in the browser with IndexedDB through idb-keyval. Logs can be saved, updated, deleted, cleared, and bulk-added locally. There is also an offline queue through localStorage for pending logs, plus a sync manager that can push device operations to the backend using an API key.
That gave the app a practical offline-friendly shape:
browser event
→ write to IndexedDB
→ update React state immediately
→ queue pending operation if needed
→ sync through backend when available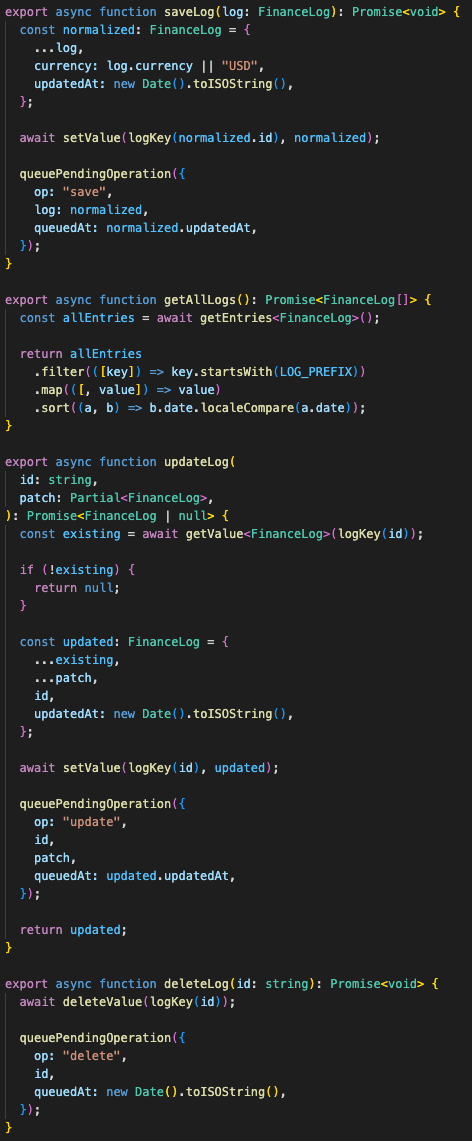
Local writes feel instant while backend sync remains explicit.
The sync path is still simple. It stores operations per device in memory on the backend. That is useful for the reference architecture, but I would not sell that as final production sync. Production sync would need persistent operation logs, conflict resolution, replay safety, and probably per-user isolation.
For this build, the useful part is the boundary:
local writes should feel instant
backend sync should be explicit
AI should not be the source of truthForecasting and anomaly detection stay deterministic
Forecasting and anomaly detection follow the same rule.
They run as separate deterministic API endpoints.
Forecasting uses Prophet against monthly expense totals. The backend fetches raw expense logs, groups them by month in Pandas, validates that there are at least two months of data, fits the model, and returns a bounded forecast payload.
It also returns MAE and RMSE when requested.
The endpoint clamps negative spending predictions to zero and adds cache headers so the frontend can avoid refetching expensive results too aggressively.
forecast request
→ validate periods
→ fetch expense logs
→ group by month in Pandas
→ fit Prophet
→ calculate metrics
→ return forecast bounds
→ cache response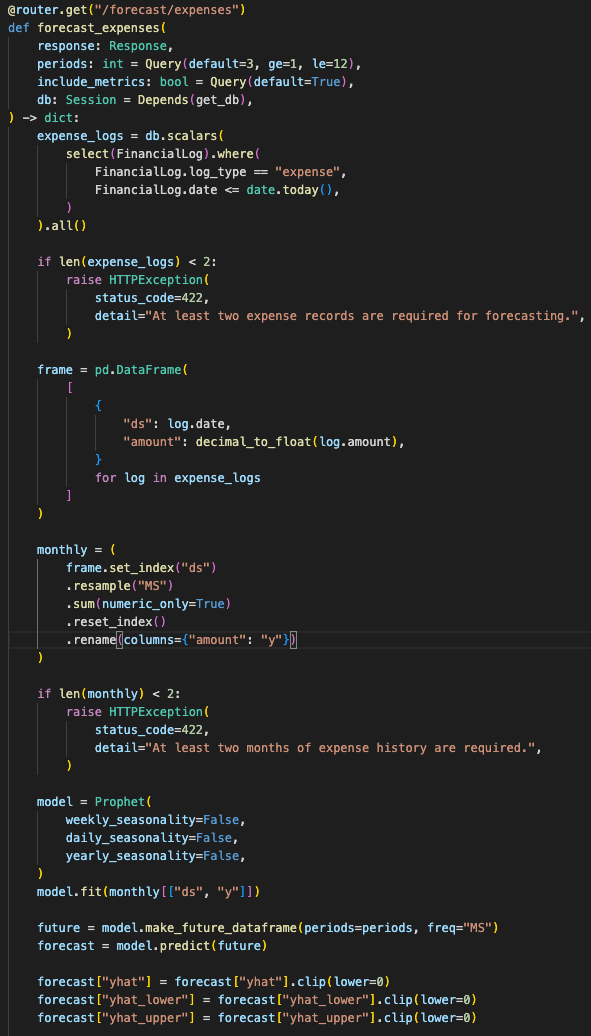
Forecasting is a backend analytics endpoint, not a language-model guess.
Anomaly detection uses IsolationForest. It pulls the latest expense records, builds features from amount, day of week, and day of month, then returns unusual transactions with a plain reason.
It also handles the low-data case safely. Fewer than ten logs returns an empty result instead of forcing the model to pretend.
anomaly request
→ fetch recent expense logs
→ require enough records
→ build date-based features
→ run IsolationForest
→ return flagged transactions
→ safe empty result on failure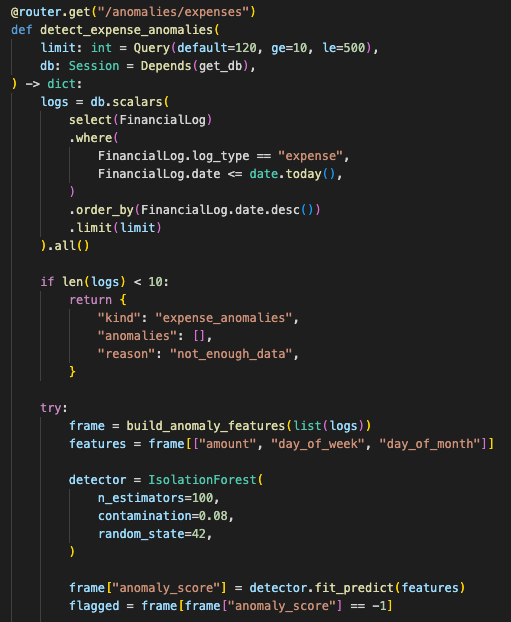
The anomaly path uses structured features and low-data guards instead of asking the LLM to spot finance anomalies from prose.
The system became safer when the AI had less authority
This is the backend pattern I wanted across the whole app.
The model can help the user talk to the system.
The system still needs normal engineering mechanisms:
- Typed schemas
- Sanitized prompts
- Normalized log types
- Indexed database fields
- Date-range queries
- Server-side aggregation
- Action validation
- Guarded deletes
- Commit and rollback behavior
- Provider timeouts
- Budget caps
- Concurrency limits
- Cache headers
- Health checks
- Deployment constraints written down honestly
The client wanted a personal AI finance tracker.
The actual build became a finance backend with an AI interface.
That difference matters because money workflows punish loose boundaries. A model can classify a phrase, draft a response, or translate intent into a structured action. It should not be trusted as the ledger, the calculator, the database, the sync engine, or the deployment strategy.
The system became safer when the AI had less authority.
Not less value. Less authority.
That is the architecture I’d keep carrying forward: use the model where language is messy, then hand off to deterministic services where the result has to be correct.
Onto the next one. Let’s keep sharpening that edge!
First written on March 20, 2025.
Want to implement this architecture in your business?
Discuss Your Project