Grounded Legal AI: Building a Research Backend Around Live Case Law
Blackletter keeps legal synthesis grounded by querying live CourtListener records first, cleaning and trimming opinion text, then sending bounded source context into the model with citation mapping and cost controls.
I’ve been working on Blackletter, a legal research assistant for US case law.
The goal is simple enough to explain: ask a legal question, retrieve relevant federal opinions, synthesize the answer, and show the source cases behind the analysis.
The architecture is where the work is.
A generic legal chatbot can answer confidently from stale context, loose prompts, or whatever the model remembers from training. That is a bad shape for legal research. The model needs to be boxed into a retrieval path, and the backend needs to control what reaches it.
The first rule I used was this:
The LLM should never be the first system of record.
For Blackletter, the first system of record is CourtListener. The backend queries live case metadata, fetches opinion text, cleans it, trims it, and then sends only bounded context into the model.
The backend controls the research handoff
The request flow looks like this:
user query
→ FastAPI endpoint
→ rate limit check
→ CourtListener search
→ relevance and authority sorting
→ parallel opinion text fetch
→ text cleanup
→ context trimming
→ Together AI synthesis
→ citation footer parsing
→ structured response with source cases
CourtListener handles source retrieval, FastAPI controls the handoff, and the model synthesizes only from bounded legal context.
I split the backend into two main paths.
The first path is search.
GET /api/searchThat endpoint does not call the LLM. It only returns case metadata, snippets, citations, dates, and source URLs from CourtListener.
That matters because not every legal research action deserves an expensive model call. Sometimes the user just needs to find the cases. A search path should be fast, cheap, and predictable.
The second path is analysis.
POST /api/analysisThat path is heavier. It searches CourtListener, takes the top cases, fetches full opinion text in parallel, builds the context packet, sends it to the model, and returns a structured answer with citations and sources.
There is also a streaming path.
POST /api/analysis/streamThat exists because full legal synthesis can take long enough to make the frontend feel dead. The streaming endpoint uses server-sent events so the UI can start rendering answer text as the model produces it.
The frontend runs search and streaming analysis in parallel.
case search
→ render case cards as soon as metadata arrives
streaming analysis
→ render answer text as tokens arriveThat made the interface feel less blocked. The source list and answer panel do not have to wait for the same backend step to finish.
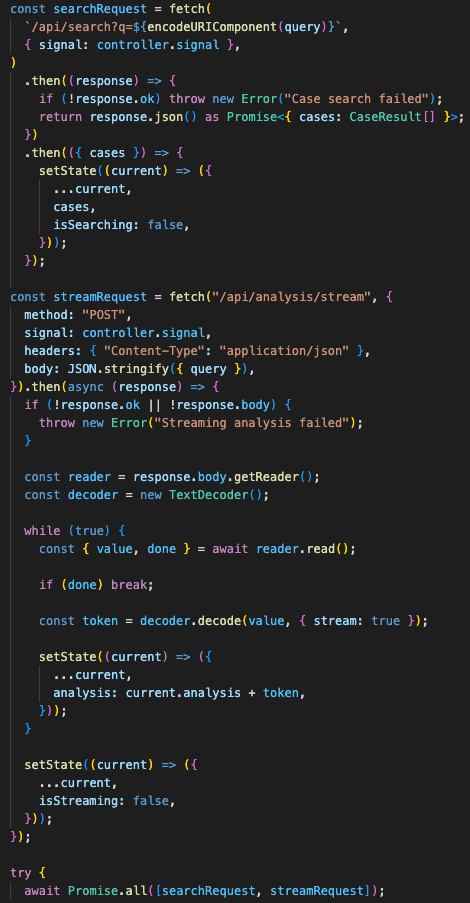
The frontend renders source cards and streamed answer text independently so legal research does not feel blocked on one long request.
Retrieval and synthesis are separate jobs
The important backend boundary is between retrieval and synthesis.
CourtListener handles legal source retrieval.
The LLM handles synthesis.
FastAPI controls the handoff.
That handoff cannot be loose.
Opinion text from public legal databases is messy. Some records have plain text. Some have HTML with citations. Some have HTML lawbox content. Some have weak snippets. Some have empty text. The backend has to normalize enough of that before the model sees it.
The CourtListener service uses this priority:
plain text
→ HTML with citations
→ HTML
→ lawbox HTML
→ empty fallbackThen it strips HTML tags and collapses whitespace.
That sounds small, but it protects the prompt budget. Legal opinions can be long. Sending raw HTML and repeated whitespace into an LLM burns money and context window.
Context size has to be controlled before inference
The next problem was context size.
If the backend retrieves three cases and one opinion is huge, that single case can dominate the prompt. Then the model gets an uneven view of the legal context.
So the LLM service trims chunks evenly.
The backend calculates a total input budget, divides it across the retrieved case chunks, and truncates anything too large.
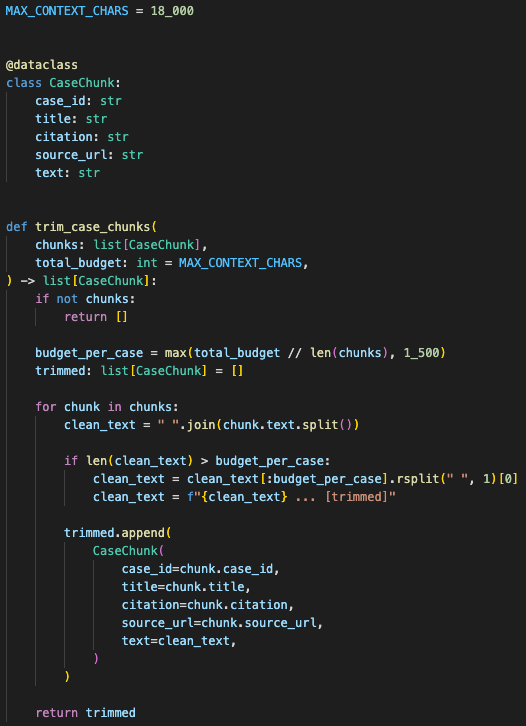
Each retrieved case gets a bounded share of the context window so one long opinion does not crowd out the rest of the source set.
This is one of those backend controls that matters more than it looks.
Without it, the answer quality becomes unstable. One oversized opinion can crowd out the other sources. The model still gives an answer, but the answer may reflect the shape of the prompt more than the actual case set.
The answer carries citation metadata
The analysis prompt also has structure.
It tells the model to organize the response by:
- Landmark Precedents
- Key Rulings
- Majority Opinions
- Concurring Opinions
- Dissenting Opinions
That is not a guarantee of legal correctness. It is a formatting and reasoning constraint. The model still has to be treated as fallible.
So the backend requires a machine-readable citation footer:
CITATIONS: [1, 2, 3]After the response comes back, the service parses that footer and returns citation IDs separately from the answer body.
answer text
→ citation footer split
→ citation IDs extracted
→ structured API response
→ frontend displays analysis beside sourcesThis gives the UI something concrete to work with. The answer is not just markdown. It has citation metadata that can be mapped back to the retrieved source list.
Missing source text should stay visible
The summarization path uses a similar shape.
GET /api/summarize/{case_id}It fetches the opinion text for a specific CourtListener case ID, checks whether enough text exists, then asks the model to produce a structured brief with Facts, Issue, Holding, and Reasoning.
If the full opinion text is unavailable, the backend returns a data-unavailable response instead of pretending the model can summarize what it does not have.
That failure mode matters.
For legal software, empty source text should be visible. Missing retrieval should not be hidden behind confident generation.
Expensive legal routes need cost controls
The other major piece is cost control.
This is a public-facing prototype shape, so the backend needs guardrails before expensive routes. Search can be relatively permissive. Analysis and summarization need stricter limits.
Blackletter uses an Upstash Redis-backed security service for three things:
- Rate limiting
- Monthly spend tracking
- Budget cutoff
The service can run fail-open locally when Redis is not configured, then enforce limits when credentials are present.
The rate limiter uses a fixed-window counter:
ratelimit:{endpoint}:{window}Different endpoints get different limits.
Search can allow more requests because it avoids the LLM path.
Analysis gets a tighter limit because it triggers retrieval, context assembly, and model inference.
The budget tracker estimates spend from prompt and completion tokens, increments a monthly Redis key, and blocks new LLM calls once the configured cap is reached.
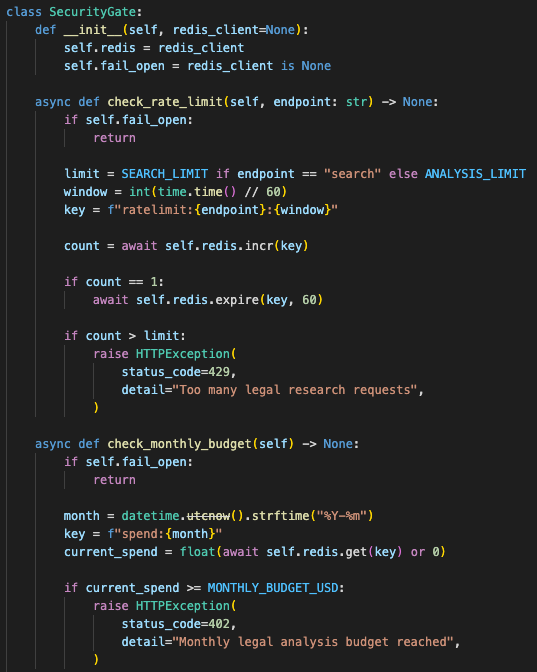
The public demo can reject expensive requests before one bug, reload loop, or curious user burns through the model budget.
This is not enterprise billing infrastructure. It is the minimum responsible version for a live demo: stop one curious user, one bug, or one reload loop from turning a small prototype into a surprise invoice.
Deployment details still matter
On application startup, the FastAPI lifespan hook initializes local database tables and checks the current Redis spend state. The health endpoint reports version, security state, and allowed CORS origins.
There is also defensive CORS parsing.
That one came from a normal deployment headache. Environment variables often pick up quotes, spaces, or trailing slashes. Starlette CORS handling can reject preflight requests if origins do not match exactly. The backend strips those values before registering allowed origins.
Small thing. Real thing.
The cache layer exists, but it is not active yet
The current architecture has a local SQLite cache service defined for answers and summaries. I’m not treating that as part of the active request path yet because the shown /analysis and /summarize routes do not currently call it.
That matters for the writeup. A cache table existing in the codebase is different from a cache layer actively protecting the request path.
The honest version is this:
The current Blackletter backend already has retrieval, synthesis, streaming, budget controls, and source mapping.
The next architecture step is wiring cache reads and writes into the expensive paths.
That would change the flow from:
query
→ retrieve
→ synthesize
→ returnto:
query
→ cache check
→ return cached answer if valid
→ retrieve only on miss
→ synthesize
→ save answer with sources
→ returnFor legal research, cache invalidation needs care. A cached answer should probably include the original query, source case IDs, generation model, timestamp, and retrieval parameters. Otherwise the system can accidentally serve an old synthesis as if it came from a fresh search.
That is the type of backend detail that matters more than the UI.
The control plane is the product
The model can write the memo. The backend has to decide what the model is allowed to see, how much it can spend, which source text counts, how stale the answer can be, and what happens when the source database returns nothing useful.
Using AI for legal research is the least interesting part of the system now.
The useful part is the control plane around the model:
- Live federal source retrieval
- Separate search and analysis paths
- Parallel opinion fetching
- Text cleanup before inference
- Bounded prompt construction
- Streaming response path
- Citation footer parsing
- Structured source mapping
- Rate limits for expensive operations
- Monthly spend cutoff
- Visible failure when source text is unavailable
That is the shape I trust more for legal AI.
The LLM is inside the system. It is not the system.
For legal work, that boundary is the whole point. The backend has to keep the research grounded, the cost bounded, and the source trail visible enough for a human to verify.
Onto the next one. Let’s keep sharpening that edge!
First written on November 12, 2025.
Want to implement this architecture in your business?
Discuss Your Project