Handling Feature Drift in Production Fraud Pipelines
A checkout fraud model stayed online while quietly blocking good customers. The fix was a separate drift monitoring loop, model/version traceability, decision logs, staged rollout, and rollback paths around the live request flow.
How’s everyone doing?
Today I’m writing about a failure that looked healthy from the outside.
The checkout flow started blocking good customers. That was the issue.
The model endpoint was still online and the API was still responding. The database was still writing records. Nothing looked broken from a normal backend health check.
But the system was making worse decisions.
The infrastructure looked fine while the product quietly hurt the business.
I had a fraud pipeline running behind a checkout flow. The backend received transaction data, prepared the features, called the model, stored the score, and returned a decision path to the app.
The basic shape looked like this:
checkout request
→ backend validates payload
→ transaction gets stored
→ features get prepared
→ model returns risk score
→ decision rule runs
→ checkout continues or gets blocked
The live request path was healthy by normal API checks, but the model decisions were drifting.
Uptime did not mean decision quality
Traffic patterns changed. The inputs coming into the model no longer looked like the inputs it had learned from. Average cart values shifted. Locations changed. Purchase timing changed. The model started treating legitimate behavior like suspicious behavior.
That is feature drift.
The backend lesson was blunt: a model-backed system needs a way to notice when reality has moved. Normal uptime checks were not enough.
A /health endpoint can tell me the API is alive. It cannot tell me whether the model is still making useful decisions.
I added a separate drift monitoring loop
So I added another layer: a monitoring worker. A scheduled backend process that looked at recent production features and compared them against the training baseline.
The first version was simple:
nightly job
→ pull recent transaction features
→ compare against training baseline
→ flag suspicious distribution shifts
→ send alert
The worker compared recent production features against the training baseline without sitting inside the checkout path.
The important part was where this worker sat. It did not sit inside the checkout request path.
Checkout should not wait for statistical checks. The drift worker ran separately, read from the database, and reported risk. It observed the system without slowing it down.
That kept the live path clean:
live checkout path:
validate → score → decide → respond
monitoring path:
read recent features → compare baseline → alert
The request loop stayed fast while the feedback loop watched whether the model was still safe to use.
For the drift check, I kept it practical.
I needed a signal that said: “The production feature distribution is moving away from what the model was trained on.”
For numeric features, that meant comparing recent live values against the training distribution. For categorical fields, it meant watching unexpected values, new country mixes, new payment patterns, and changes in frequency.
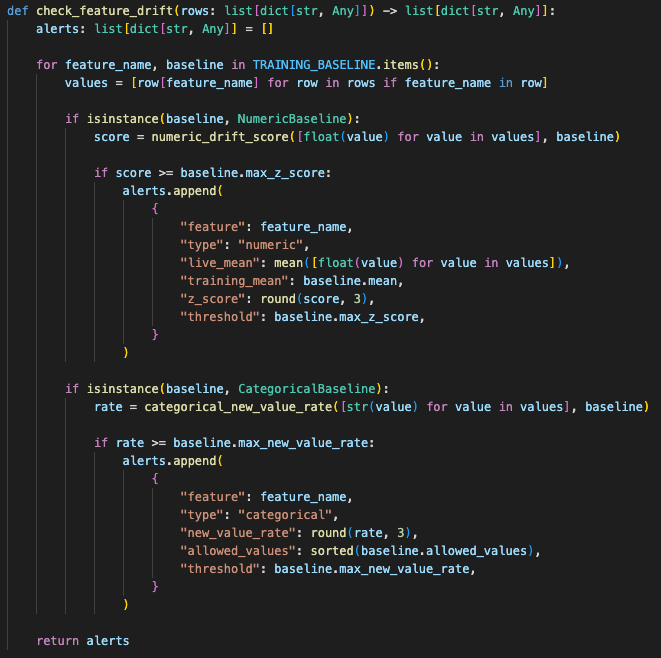
The worker pulled recent production feature rows, compared them with saved baselines, and alerted when thresholds crossed.
Model swaps needed versioned traceability
Once feature drift was detected, the system still needed a safe way to change the model.
This is where backend integration matters.
A retrained model should not be copied onto a server by hand and prayed over. The serving layer needs a controlled swap path. The model became a versioned runtime dependency.
The API needed to know which model version it had loaded. The logs needed to show which version produced which score. The database needed enough traceability to compare old and new behavior.
So the response path started carrying more operational context:
request_id
model_version
feature_schema_version
risk_score
decision
timestamp
Each decision carried enough model and feature metadata to debug false positives later.
That gave me a safer way to debug false positives.
If a user was blocked incorrectly, I could see which model made the decision, what feature schema was used, and what score came back. Without that, every incident becomes guessing.
The rollout path had to be boring
For deployment, I wanted the model swap to be boring and reliable.
New model loads in a separate environment. It receives a small slice of traffic. Logs are checked. If it behaves cleanly, more traffic moves over.
The shape:
current model
→ serving live traffic
new model
→ loaded separately
→ receives small traffic slice
→ logs compared
→ promoted if clean
The old model stayed available while the new version proved itself under a small slice of real traffic.
This protected the checkout flow. The API did not need to stop accepting requests just because a new model was being tested. The old version stayed available while the new version proved itself under real traffic.
The first rollout was intentionally conservative:
load new model version
route small traffic slice
compare block rate
watch errors
check latency
check feature parsing
promote or roll back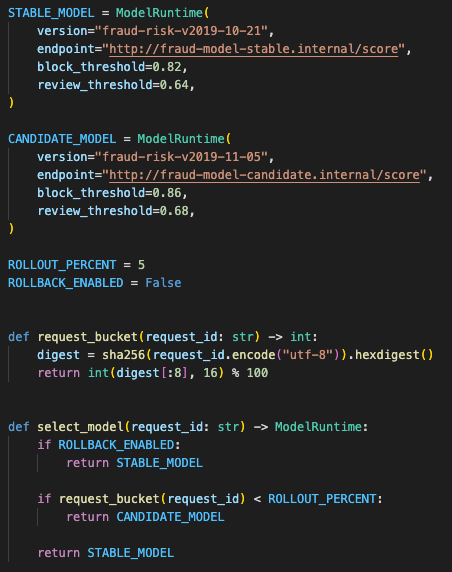
The router sent a small percentage of requests to the new model while logging model version per decision.
The edge case I cared about most was silent failure.
A new model can return valid-looking scores while being wrong in a new way. So the rollout could not only check whether the API returned 200. It had to check decision behavior: block rate, review rate, feature parsing errors, latency, and sudden changes in score distribution.
That is the annoying part of model deployment.
The endpoint being alive is the lowest bar. The decision quality still has to be watched.

The rollout dashboard compared latency, errors, block rate, score distribution, and model version side by side.
The final backend shape became less fragile:
checkout API
→ feature store / transaction records
→ model serving layer
→ decision logs
→ drift worker
→ alert
→ retrain
→ staged rollout
The final system connected live scoring with a feedback loop for drift detection, retraining, staged rollout, and rollback.
Result
This was the useful lesson from the build:
A model-backed backend needs two loops.
The request loop handles the live user path. The feedback loop watches whether the model is still safe to use.
If the feedback loop is missing, the first monitoring system becomes customer support tickets. Bad place to find out the model has drifted.
The fix was a set of boring backend pieces connected properly:
- stored features
- model versioning
- decision logs
- scheduled drift checks
- alerts
- staged rollout
- rollback path
Those pieces made the system easier to operate.
When the input data changed, the backend had a way to notice. When the model needed replacement, the serving layer had a way to swap it without freezing checkout. When a decision looked wrong, the logs had enough context to trace it.
A fraud model is only finished when the system around it can detect decay, replace it safely, and explain what happened when a decision goes wrong.
Onto the next one. Let’s keep sharpening that edge.
First written on November 05, 2019.
Want to implement this architecture in your business?
Discuss Your Project