Highground: Building a Backend Pipeline for Market Intelligence
Highground turns market intelligence into an async backend pipeline: URL ingestion, scraping, DOM cleanup, Redis caching, model routing, WebSocket progress, streamed strategic insight, route-specific limits, and export boundaries.
The first mistake was treating market intelligence like a chatbot answer.
A connection introduced me to an MSME that wanted to use AI to monitor and scale the business. The request sounded broad at first: use AI to understand the market, improve visibility, and make better decisions.
That can easily turn into a useless chatbot.
Ask it for advice. Get a generic answer. Ask again next week. Get a slightly different generic answer.
That was not worth building.
The useful version was a repeatable monitoring workflow:
submit a business URL
→ extract website signals
→ check technical and content structure
→ compare against competitor context
→ score SEO and GEO readiness
→ stream the analysis as it runs
→ return a report the owner can act onI called the system Highground.
The name fit the problem. The goal was to give the business a higher view of its web presence, not another dashboard full of vanity metrics.
The backend shape mattered more than the AI prompt.
A market-intelligence system has to ingest messy websites, survive blocked pages, avoid wasting tokens on raw DOM junk, keep provider usage bounded, and still return something useful to the UI. If the model gets raw page noise and the frontend waits 30 seconds with a spinner, the system feels broken even if the final text is decent.
So I built Highground around a pipeline, not a conversation.
URL input
→ frontend normalizes URL
→ Express backend starts async analysis
→ analysisId is created
→ HTTP 202 returns immediately
→ WebSocket subscribes to the analysis stream
→ scraper fetches and sanitizes the page
→ Redis checks cached scrape and AI outputs
→ small model extracts structured signals
→ expert model streams strategic analysis
→ partial results patch the UI
→ final report is emitted over WebSocket
→ export routes generate JSON, CSV, or report output
The system treats market intelligence as a running backend job, not a single chatbot response.
Analysis runs as an async job
The first backend decision was to make analysis asynchronous.
A normal request-response flow was too fragile for this workload. Scraping can take time. AI calls can take time. Competitor extraction can take time. A frontend should not sit there waiting for one large response while the backend runs every stage.
The analyze endpoint returns 202 Accepted immediately with an analysisId.
That ID becomes the correlation key for the job.
The backend keeps working after the HTTP response is already done.
POST /api/analyze
→ validate URL
→ create analysisId
→ return 202
→ processAnalysis runs in background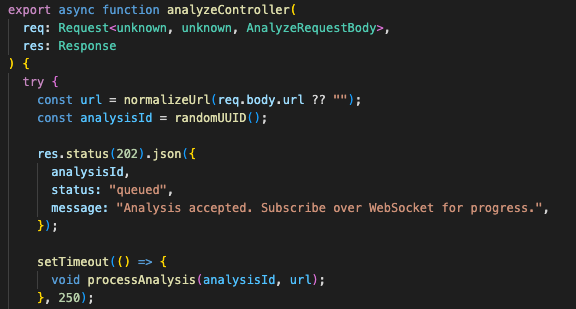
HTTP starts the job and returns a correlation ID. The backend pipeline continues in the background.
The frontend then opens a WebSocket connection and subscribes to that analysisId.
That gave me a cleaner split:
HTTP starts the job.
WebSocket carries the job state.The UI can show scraping, analyzing, generating, and complete states without polling. It also receives partial results before the heavier reasoning finishes.
That matters because perceived latency is part of the product. If the user sees nothing until the expert model finishes, the system feels slow. If the UI receives structural data early, then streams insight while the backend finishes the expensive work, the system feels alive and controllable.
WebSocket replay fixes the fast-cache race
The WebSocket path also needed its own reliability fix.
Cached jobs can complete almost instantly. That sounds good until the backend emits the final result before the frontend finishes receiving the 202 response and opening the socket. The result exists, but the UI misses it.
So the WebSocket service buffers messages by analysisId.
When a client subscribes late, the service replays the buffered events.
That fixed the race condition without forcing the frontend into polling.
There is also a short grace period before processing begins. It gives the frontend time to subscribe before fast cache hits complete. It is not elegant distributed systems theory. It is a practical fix for the way browsers, HTTP responses, and WebSocket subscriptions actually race each other.
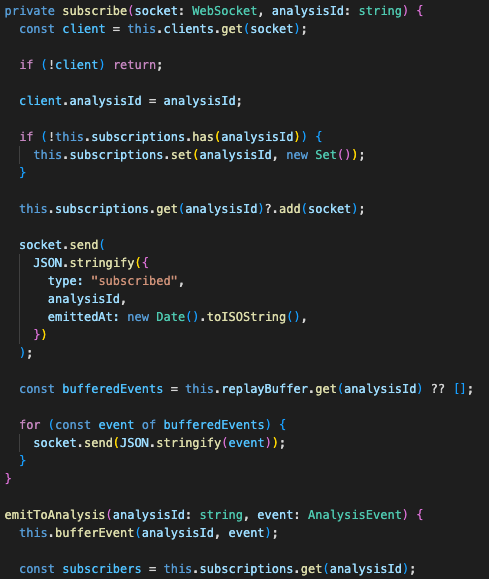
Late subscribers can still receive progress and final events for their analysisId instead of missing fast cache-hit results.
Scraping cleans the page before inference
The ingestion layer was the next constraint.
Web pages are noisy. Passing raw HTML into an LLM is wasteful and usually makes the reasoning worse. A page includes scripts, styles, nav bars, footers, SVGs, cookie banners, ads, tracking markup, and layout junk.
Highground strips that before inference.
The scraper uses Axios to fetch the page with a timeout and redirect cap. Cheerio parses the HTML. The backend removes noisy elements before extracting title, meta description, language, headers, links, image count, text content, word count, and load time.
The model should not count words.
Node can count words.
The model should not infer whether a title tag exists.
Cheerio can extract it.
That boundary kept the AI focused on reasoning over cleaned signals instead of wasting tokens on mechanical parsing.
scrape URL
→ parse HTML
→ remove scripts/styles/nav/footer/header/ads/cookie banners
→ extract title and description
→ collect h1/h2/h3 headers
→ build text content
→ count words
→ record load time
→ cache structured scrape result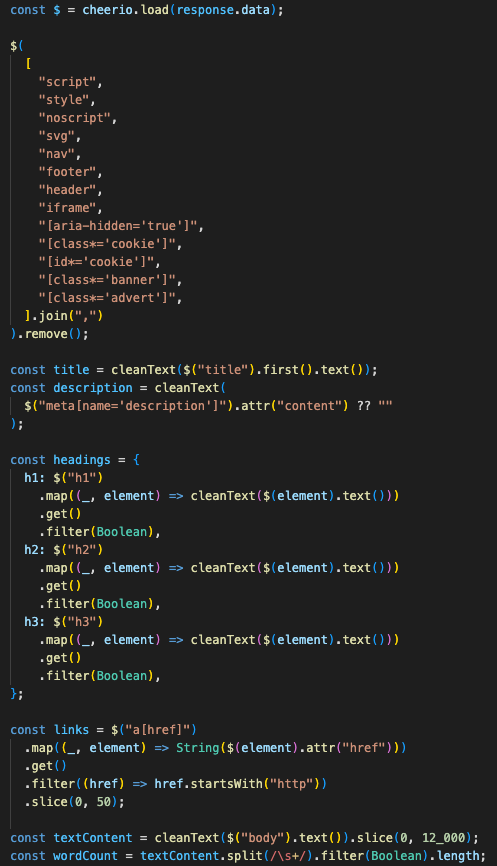
The backend extracts structured page signals before any model sees the website content.
The scraper also has a fallback path.
Some sites block scraping. Some sites are JavaScript-heavy and return almost no useful static HTML. Some requests fail. In those cases, the service falls back to a synthetic HTML body based on the domain so the demo path does not crash.
That is useful for a prototype, but it has to be described honestly.
Fallback data keeps the pipeline running. It does not turn blocked pages into verified live web facts.
For production, I would make that state visible in the report: live scrape, cached scrape, partial scrape, or fallback scrape. The current system already has the basic boundary. The next step would be exposing scrape confidence to the user.
Redis handles cache and spend state
Redis sits behind two parts of the system.
First, caching.
Scraped pages and AI outputs are cached so the same domain does not keep burning network calls and model tokens. The cache key is derived from the URL or request text. Cached outputs can be returned quickly and replayed through the same UI flow.
Second, budget control.
Highground tracks AI spend in micro-units under a Redis key. Before an AI request runs, the gateway checks whether the monthly cap has been reached. If the cap is exceeded, the request is blocked and the system returns a fallback response instead of blindly calling the provider.
Redis can fail or be missing in development, so the service falls back to an in-memory map.
That is fine for local work and controlled demos. Multi-worker production needs real Redis because in-memory state splits across processes.
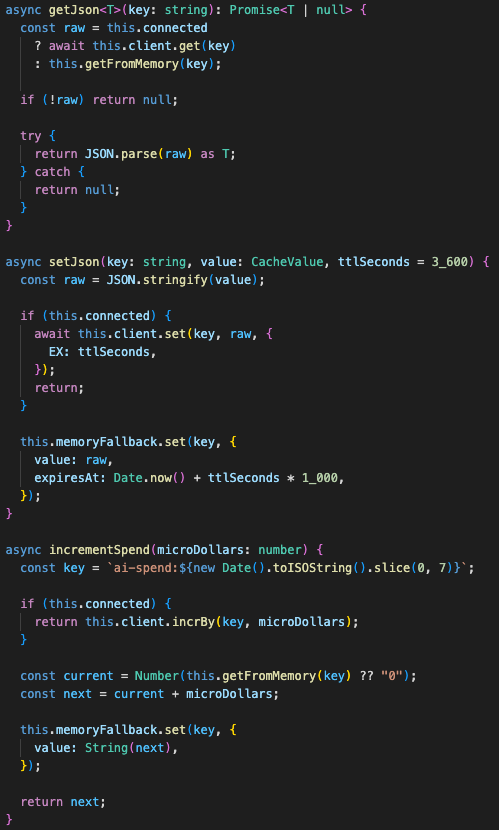
Redis gives the pipeline shared cache and budget state while local development can fall back to memory.
Model routing follows task shape
The AI layer is routed by task.
Highground does not send everything to the heaviest model.
Sentiment, keywords, and competitor extraction go through the faster structured path. The prompt forces JSON output and the backend parses it aggressively. It strips markdown fences, removes reasoning blocks, finds the first JSON object or array, validates that it parses, and falls back safely if it does not.
Heavier insight generation goes to the expert path.
That path has a stricter system prompt:
- No marketing fluff
- Banned words
- No repetition
- No markdown bolding
- Maximum three sections
- Observation
- Implication
- Action
This is not branding theater. It is output control.
The UI expects structured strategic content. The report expects structured strategic content. The downstream components should not need to guess whether the model returned a paragraph, a bullet list, a motivational slogan, or a half-finished thought.
The model route became:
keywords
→ small model
→ JSON array
sentiment
→ small model
→ JSON object
competitors
→ small model
→ JSON array
insights
→ expert model
→ streamed structured text
vision audit
→ standby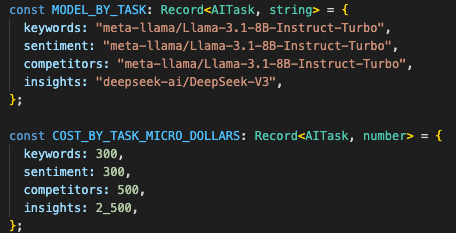
Small structured extraction jobs and heavier strategic synthesis run through different model paths.
The job emits partial results before the final report
The analysis job runs these tasks in parallel.
After scraping, the backend starts sentiment extraction, keyword extraction, expert insight generation, and competitor extraction. It does not wait for one model call to finish before starting the next.
The first resolved outputs patch the UI as partial results. The heavier insight stream continues in the background.
That gave the frontend a tiered loading path:
Tier 1: structural demo data and baseline scores
Tier 2: keywords and sentiment
Tier 3: expert strategic insight and competitors
Final: complete result payloadThis was important because a market audit has multiple shapes of work. Some work is cheap and deterministic. Some work is cheap and model-assisted. Some work is expensive and generative. Treating all of it as one blocking AI call would make the system slower and harder to control.

The pipeline emits useful partial state while slower model work continues.
The frontend tracks a running job
The frontend mirrors that architecture.
The useAnalysis hook starts the job, stores the analysisId, subscribes to WebSocket updates, handles partial results, merges final results, and supports cancellation through an AbortController.
The useWebSocket hook builds the socket URL from environment configuration, normalizes local development edge cases, subscribes with the analysis ID, accumulates streamed tokens, and reconnects on unexpected disconnects.
That kept the UI state aligned with the backend job lifecycle.
The frontend was not pretending the analysis was a single API response.
It was tracking a running job.
start analysis
→ set status to scraping
→ call API
→ receive analysisId
→ open WebSocket
→ receive progress events
→ patch partial result
→ accumulate streamed insight tokens
→ receive complete event
→ render final report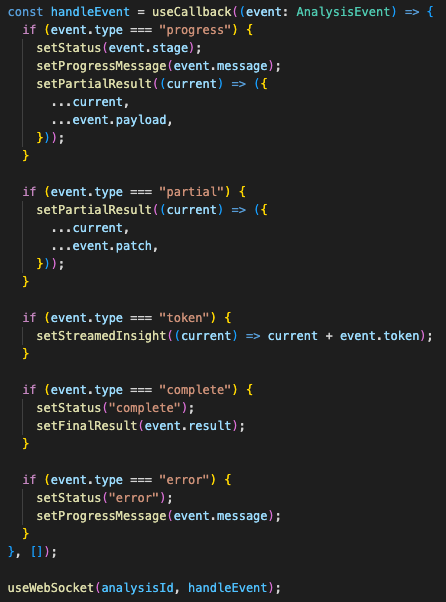
The client state model follows the backend job lifecycle instead of assuming one blocking response.
The strategic insight component also has its own cleanup rules.
The expert model can emit reasoning tags or preamble text. The component strips <think> blocks, finds the first required header, and only renders the structured sections: Observation, Implication, Action.
That is a frontend guardrail around backend prompt control.
The backend asks for a shape. The frontend still defends against drift.
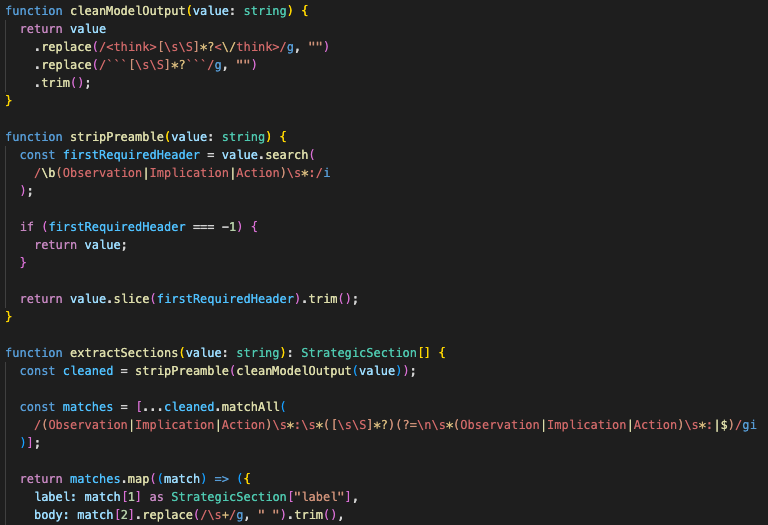
The renderer cleans streamed model output and keeps the final view locked to the expected strategic sections.
Rate limits follow endpoint cost
The same philosophy shows up in request validation.
The analysis route validates that a URL exists, requires http or https, and applies a stricter analysis-specific rate limit: 10 analysis requests per 15 minutes per IP.
Exports have their own limiter: 5 exports per hour.
That split matters because not all endpoints have the same cost profile. A health check is cheap. A market analysis is expensive. A report export is heavier than a normal metadata request. The backend should not protect all routes with the same blunt limit.
The Express app also has the usual production guardrails:
- Request IDs
- Helmet security headers
- Strict CORS checks
- Body size limits
- Global rate limiting
- Response-time headers
- Morgan logging
- Centralized error handling
- Health checks
- Graceful shutdown for Redis and WebSockets
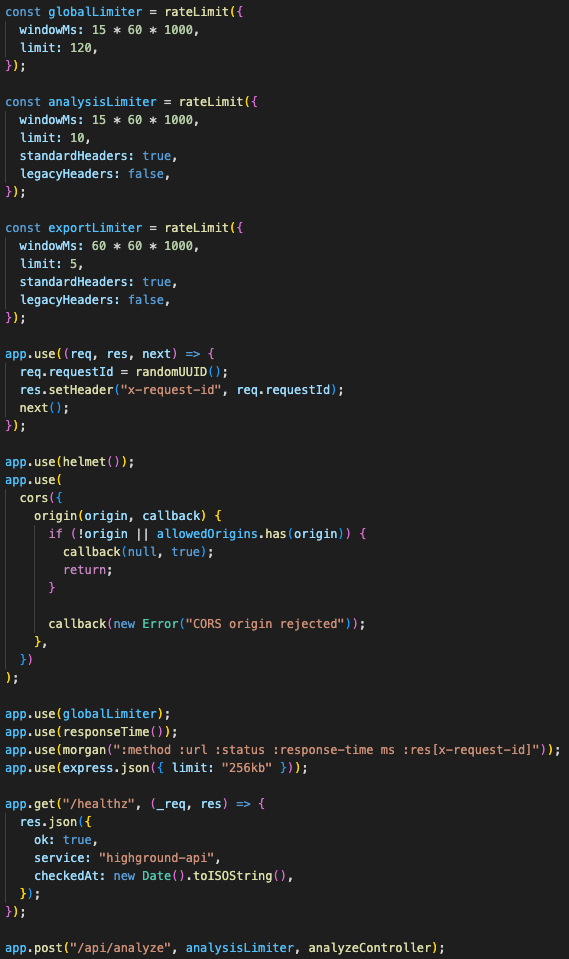
The app treats security headers, request tracing, body limits, rate limits, centralized errors, health checks, and shutdown as part of the product boundary.
Model usage needs operational visibility
Analytics were added around the same idea.
Highground tracks total requests, successes, errors, latency samples, current spend, remaining budget, and active model names. Latency data is kept in Redis when available and used to calculate average and p95 latency.
That turns model usage into something observable.
For a small business prototype, that may sound like too much. It is not.
The moment model calls cost money and analysis jobs take seconds, the system needs basic operational visibility. Otherwise the owner only finds out something is wrong when the app feels slow or the bill is higher than expected.
Exports are scoped, not oversold
The export path is scoped but useful.
Highground can export market data as JSON or CSV. SEO analysis can also be exported as JSON or CSV. The report route builds a report data object from the live analysis output and sends a buffer back to the client.
The current report service generates an HTML template and returns it as a buffer. I would not call that a finished PDF renderer yet. It is a report export path with the skeleton for a PDF workflow.
That is enough for the architecture stage. The next production step would be a real HTML-to-PDF renderer and clearer report provenance around live, cached, and fallback data.
Competitor intelligence has an interface boundary
The competitor side is also scoped.
Some competitor dashboard routes use demo market intelligence data. Specific competitor analysis can optionally run live URL analysis against a competitor domain. AI-generated recommendations sit on top of that data.
That is useful for the prototype, but it should not be oversold as a complete live competitor-intelligence crawler.
The important part is the interface boundary:
market data source
→ competitor controller
→ optional live URL analysis
→ AI recommendation layer
→ benchmark summary
→ frontend matrixThat boundary can accept better data later without rewriting the whole product.
The useful part is the pipeline around the model
This is the architecture lesson from Highground.
The MSME did not need a chatbot that says “improve your SEO.”
They needed a repeatable system that could turn a site into structured signals, keep the expensive reasoning path bounded, stream progress while the work runs, and produce an output that could become a business decision.
The backend mechanisms made that possible:
- Async jobs instead of blocking requests
- AnalysisId correlation
- WebSocket progress streams
- Buffered event replay
- Defensive scraping
- DOM cleanup before inference
- Redis caching
- In-memory fallback for development
- Model routing by task type
- JSON extraction for structured outputs
- Streamed expert synthesis
- Hard budget checks
- Route-specific rate limits
- Centralized errors
- Latency and spend metrics
- Export boundaries
- Honest fallback behavior
AI was useful in the system because it had a job.
It did not own ingestion.
It did not own caching.
It did not own progress state.
It did not own cost control.
It did not own the report pipeline.
It turned structured signals into strategy after the backend had already shaped the work.
That is the part I want to keep sharpening with Highground: use AI where interpretation is valuable, but build the pipeline so the business is not depending on a single expensive prompt to understand itself.
Onto the next one. Let’s keep sharpening that edge!
First written on January 22, 2026.
Want to implement this architecture in your business?
Discuss Your Project