Medical Research Synthesis: Keeping PubMed Retrieval Separate From LLM Reasoning
MedIntel keeps PubMed retrieval, article normalization, bounded synthesis, and frontend evidence display as separate layers. The model writes from retrieved source objects instead of pretending to know the medical literature from memory.
I’ve been building MedIntel, a medical research assistant for PubMed literature synthesis.
The starting problem was simple.
A normal chat interface can make medical literature sound cleaner than it really is.
That is risky.
Medical abstracts are dense. They contain cohorts, outcomes, adverse events, p-values, confidence intervals, eligibility criteria, publication dates, and sometimes conflicting findings. If the model turns all of that into one smooth paragraph, the output can feel useful while quietly losing the details that matter.
That is the failure mode I wanted to avoid.
So I built MedIntel around a stricter rule:
PubMed retrieval comes first. LLM reasoning comes second.
The model should not be asked to “know” the literature from memory. It should receive a small, explicit set of retrieved articles and synthesize from that bounded context.
The backend starts with retrieval
The backend flow looks like this:
research query
→ FastAPI endpoint
→ safety gate
→ PubMed search
→ PubMed XML fetch
→ article normalization
→ capped article set
→ bounded synthesis payload
→ streaming LLM response
→ frontend research layout
Retrieval, normalization, synthesis, and frontend display stay separate so the model does not become the evidence layer.
The first backend boundary is retrieval.
MedIntel does not scrape random medical pages.
The PubMed service uses NCBI E-Utilities through Biopython Entrez. It searches PubMed for IDs, fetches article records as XML, then turns the returned metadata into structured article objects.
Each article carries:
PMID
title
abstract
journal
authors
publication date
PubMed URLThat matters because the frontend and synthesis engine need stable source objects, not loose text blobs.
A research result should still be traceable after it leaves the retrieval layer.
The search request is also capped.
The request model requires a real query, and the limit is bounded between 1 and 10 articles.
For the normal frontend search path, it sends 5.
That cap is deliberate.
Medical synthesis gets worse when the backend blindly shoves too much text into context. Ten dense abstracts can already be enough to stress the model. Fifty abstracts would mostly turn the system into a compression gamble.
The PubMed route also runs the blocking retrieval work in a threadpool.
PubMed access through Entrez is synchronous. Calling it directly inside the async FastAPI path would block the event loop. The route wraps the search call with run_in_threadpool, so the server has a cleaner separation between async request handling and blocking external I/O.
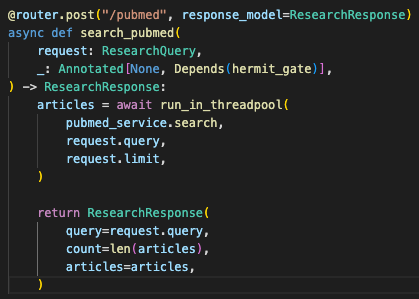
The async route keeps blocking PubMed retrieval out of the event loop while preserving a typed response contract.
Normalization keeps source objects stable
The second backend boundary is normalization.
PubMed XML is not a nice JSON payload ready for the UI.
The service has to pull fields from nested records:
MedlineCitation
→ Article
→ Journal
→ Abstract
→ AuthorList
→ PMIDSome abstracts come as multiple parts. Some fields are missing. Some author entries have LastName and Initials. Others use CollectiveName.
The service handles those cases and still returns the same Article shape.
If one paper fails to parse, it logs the failure and continues with the rest of the result set.
That is the right behavior for a research search feature. One malformed article should not kill the whole query.
Synthesis is bounded by retrieved articles
The third boundary is synthesis.
The synthesis endpoint does not accept arbitrary text.
It accepts a typed payload:
query
articles[]The request requires at least one article and caps the article list at 10.
That keeps the synthesis layer from becoming an open text dump.
Before sending articles to the model, the LLM service caps each abstract at 1,500 characters.
That is not a perfect medical safeguard. It is a practical prompt-budget safeguard.
The backend is saying: this system synthesizes from a small batch of retrieved abstracts, not from unlimited pasted literature.
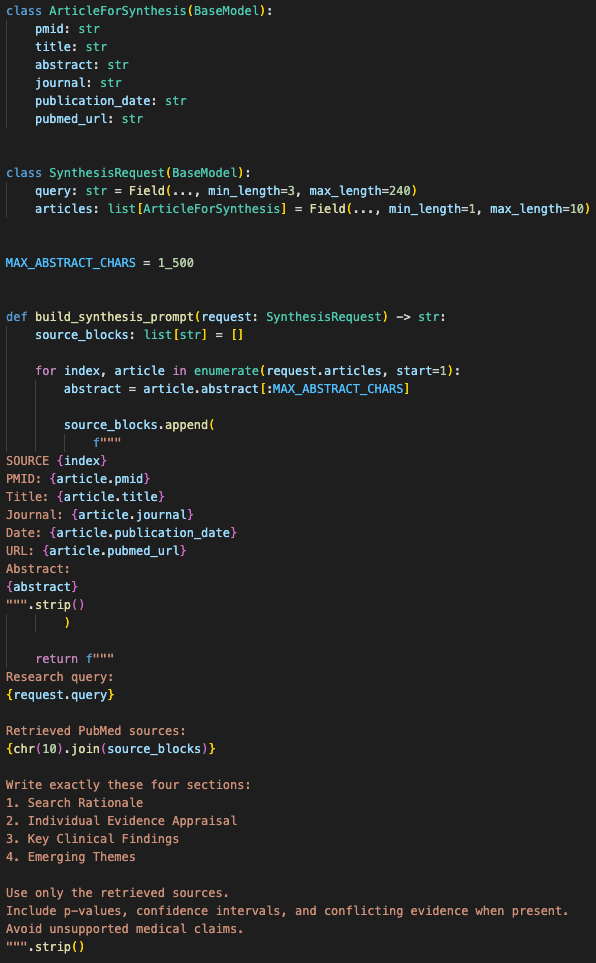
The synthesis layer receives a bounded list of source articles instead of arbitrary pasted medical text.
The prompt shape is also constrained.
The model has to write exactly four sections:
- Search Rationale
- Individual Evidence Appraisal
- Key Clinical Findings
- Emerging Themes
That structure matters because medical synthesis should not collapse into a generic essay.
The frontend expects those section markers and parses the streamed markdown into a research dashboard.
This is not JSON-schema enforcement. I’m not pretending it is.
The backend validates the request shape. The prompt constrains the response format. The frontend parses the expected headers.
That is weaker than full structured output validation, but it is honest, usable, and good enough for this stage of the system.
The system prompt also pushes the model toward hard data:
- Include p-values if present
- Include confidence intervals if present
- State conflicting evidence when evidence conflicts
- Avoid fluff
- Keep the output dense
That does not guarantee perfect medical accuracy.
It does reduce the chance of the model drifting into a polished narrative summary with no useful evidence anchors.
Streaming keeps synthesis usable
The synthesis path streams output.
The FastAPI route returns a StreamingResponse, and the LLM service yields chunks as they arrive from Together AI.
The frontend reads the response body with a stream reader and updates the synthesis panel incrementally.
That made the product feel more responsive without hiding the fact that long-form synthesis takes time.
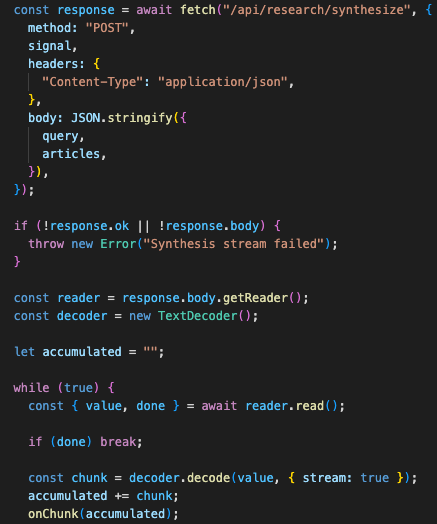
Streaming gives the frontend useful progress while the synthesis is still running.
The frontend also supports stopping the synthesis stream.
That matters in research workflows. A user may search the wrong term, realize the article set is bad, or just want to cancel a long generation. The browser keeps an AbortController for the active synthesis request and can cut it off.
The safety layer protects the public demo path
The fourth boundary is safety and demo protection.
Both PubMed search and LLM synthesis go through the Hermit Gate dependency.
That dependency checks two Redis-backed controls when Upstash credentials are configured:
- Monthly spend limit
- Global request rate limit
The monthly budget check reads a spend key for the current month. If the stored spend is already over the configured limit, the route returns 402.
The rate limiter increments a minute-bucket key and rejects requests after the configured global limit.
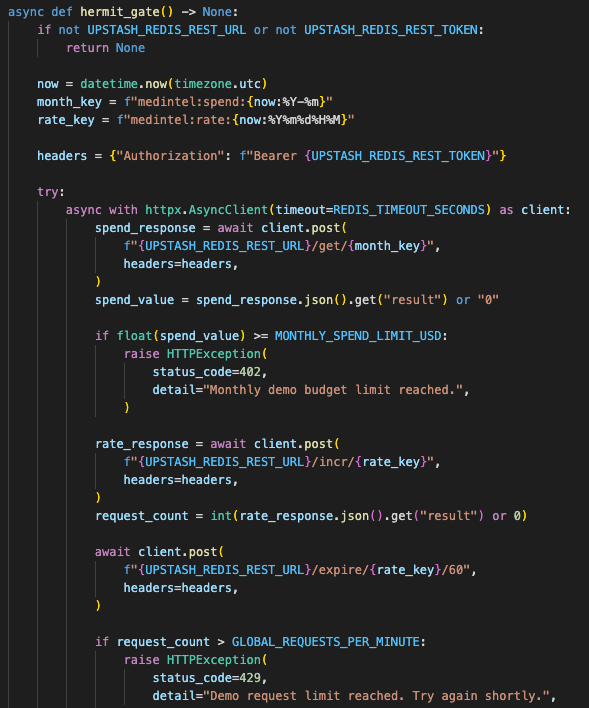
The safety gate gives the demo a basic cost and request boundary without turning it into full billing infrastructure.
This is not full billing infrastructure.
The README is honest about that. The spend tracker is a read-only kill switch unless an external mechanism increments the budget key.
That distinction matters.
A budget key that is only read is useful as an emergency brake, but it is not complete usage accounting.
For this build, that is acceptable as demo protection. For production, usage tracking has to be wired into the actual LLM call path.
The rate limit is also global, not per-IP.
That means it protects the demo from broad request spikes, but it does not isolate users cleanly. A production version would need per-user or per-IP counters, preferably with authenticated identity where possible.
The safety layer is still worth having.
A public medical research demo should not have unlimited search and synthesis endpoints exposed with no cost boundary.
The NLP path is assistive, not clinical validation
The NLP route is separate.
MedIntel has an NLP service that tries to load en_core_web_sm through spaCy. If the model is unavailable, it falls back to a regex-based heuristic extractor.
That gives the app a basic entity extraction path without making the whole demo fail because a local NLP model was not installed.
The fallback looks for capitalized phrases and common suffixes that may indicate drug names or conditions.
It is not clinical-grade medical NER.
I would not use it as a claim validator.
In the current architecture, the NLP endpoint is best understood as a research-assist layer: useful for detecting terms, debugging query intent, and showing how deterministic preprocessing can sit beside LLM synthesis.
It does not yet enforce claim-level validation against the generated output.
That is an important limitation.
The earlier version of this post would have overstated this part. It would be easy to say, “The system drops any LLM claim that cannot be linked to spaCy tags.”
The code does not do that.
The honest version is better:
MedIntel retrieves real PubMed records, keeps article metadata structured, caps the synthesis payload, prompts the model into a fixed report shape, streams the answer, and keeps source articles visible beside the synthesis.
That is a solid architecture foundation.
It is not yet a clinical validation engine.
The frontend keeps evidence visible
The frontend reinforces the source-first shape.
Search results are shown as source evidence, not just hidden context.
Each card includes:
journal
publication date
authors
PMID
title
abstract snippet
source link
copyable citationThat keeps the user close to the original literature.
The synthesis panel then turns the model’s markdown into a four-part report. It does not just dump a wall of generated text.
The sections match the backend prompt:
- Literature Selection Rationale
- Individual Evidence Appraisal
- Key Clinical Findings
- Emerging Themes and Consensus

The UI keeps source evidence visible beside the generated synthesis instead of hiding retrieval inside the model call.
There is also a per-article deep dive.
Each result card can send a single article back through the synthesis endpoint with a query asking for a concise appraisal of that specific paper.
That is a useful workflow split:
batch synthesis for a group of papers
single-paper appraisal for deeper review
source link for manual verificationThe app also adapts frontend article objects aggressively before calling the backend.
It forces fields into strings, ensures authors are always an array, fills missing dates, and prevents malformed payloads from triggering avoidable Pydantic validation errors.
That is not glamorous, but it saves time.
Typed backend contracts only help if the frontend respects them.
Demo mode must be labeled honestly
The current service also has a demo-mode fallback.
If the Together client is not configured, the LLM service streams a local synthesis preview instead of crashing the UI.
That is useful for portfolio demos because the app can still show the full interaction pattern without exposing an API key.
But it has to be labeled clearly as demo mode.
Generated medical synthesis should never pretend to be live model output if it came from fallback text.
The current fallback says that directly.
That is the right call.
The model is not the evidence layer
The big lesson from this build is that medical AI needs more boring boundaries than people expect.
The risky part is not only whether the model can explain immunotherapy, cardiology, neurology, or oncology.
The risky part is whether the system lets the model silently change the shape of the evidence.
A research assistant needs retrieval discipline.
It needs source objects.
It needs limits.
It needs visible citations and PMIDs.
It needs failure states.
It needs a UI that keeps original evidence close to the generated synthesis.
The model can help write the synthesis. The backend has to decide what counts as evidence before the model starts writing.
For MedIntel, the current boundary is clear:
PubMed retrieves the source records.
FastAPI normalizes and limits them.
Together AI synthesizes from bounded context.
The frontend displays the synthesis beside the evidence.That is a safer foundation than asking a general chatbot to remember, summarize, and structure medical literature in one loose conversation.
There is still work to do.
The next version should add real claim-level validation:
- Extract study arms
- Extract sample sizes
- Extract outcomes
- Extract adverse events
- Extract p-values and confidence intervals
- Map generated claims back to source IDs
- Reject unsupported claims
- Track spend at the actual LLM call site
- Separate rate limits per user or IP
That is the path from research assistant to more serious biomedical review tooling.
For now, MedIntel is the first clean version of the architecture: live PubMed retrieval, bounded synthesis, streaming output, structured source cards, and enough backend guardrails to keep the model from becoming the whole system.
Onto the next one. Let’s keep sharpening that edge!
First written on September 9, 2025.
Want to implement this architecture in your business?
Discuss Your Project