Moving Past Flask: FastAPI, Async Requests, and Backend Workload Boundaries
A Flask model endpoint backed up under load because database I/O and PyTorch inference were mixed inside one synchronous request path. The fix was moving to FastAPI with async coordination, explicit Pydantic contracts, and a clear boundary around synchronous inference.
Today, the endpoint was not failing because the model was wrong. It was failing because the backend was waiting in the wrong places. This is the challenge I’ll be working through this post.
I had a model-backed API running behind a Flask service. From the outside, the route looked simple enough: receive a request, check the payload, fetch a bit of metadata, run inference, write the result, return a response.
Normal backend work, just with a model in the middle.
The actual request path looked closer to this:
request comes in
→ validate payload
→ fetch metadata from database
→ prepare input
→ run PyTorch inference
→ write result/log
→ return response
The route mixed database I/O, validation, PyTorch inference, logging, and response formatting inside one request path.
Locally, this felt fine. Under light traffic, also fine.
Then I started load testing and the behavior got weird. Requests were not failing all at once. They were backing up. A few workers would get busy, then the queue would grow, then response times would stretch, then the load balancer would start seeing failures.
The code “worked,” but the service did not hold up under pressure.
The request path had changed
My first version used Flask because Flask was familiar and fast to ship. I had already used it for backend routes, dashboards, and earlier model endpoints. For small services, it made sense.
But this endpoint was no longer just a small route returning data.
It had mixed work inside one request:
- database I/O
- JSON parsing
- validation
- model inference
- logging
- response formatting
Some of that work spends time waiting, while some of it burns CPU.
WSGI handles requests synchronously. A worker takes a request and stays occupied until the whole thing finishes. If the request is waiting on the database, the worker is occupied. If the request is running inference, the worker is occupied. If enough requests arrive together, all workers get pinned and new requests wait.

Each synchronous worker stayed occupied across database waits, model inference, and result writes.
The lazy fix was obvious: add more workers, add more machines, increase the instance size.
That would probably buy time. It would also turn a backend design issue into a monthly bill. I did not want the default answer to be more compute, especially when part of the request path was waiting on I/O and part of it needed a clearer execution boundary.
FastAPI gave the route a better shape
So I moved the serving layer to FastAPI because the request path had changed.
FastAPI gave me ASGI, async request handling, and a cleaner way to separate the parts of the route that were waiting from the part doing heavy work.
The new path looked like this:
request enters ASGI server
→ async route accepts and validates payload
→ async database call fetches metadata
→ synchronous inference runs behind a boundary
→ async database write stores result
→ response returns with trace/result
The ASGI layer handled request coordination and I/O waits while inference stayed behind a clear synchronous boundary.
The important part was not just writing async def because that would be fake async.
Database calls and network waits can benefit from async because the server can keep doing other work while waiting.
PyTorch inference is different. That is compute work. If I block the event loop with model inference, the async server freezes anyway.
Different framework, same mistake, so I split the work honestly.
The async layer handled request coordination:
- accept connection
- parse JSON
- validate payload
- fetch metadata
- write result
- return response
The sync layer handled model execution:
- prepare tensor/input
- run PyTorch
- produce prediction

I/O work stayed on the async coordination path. PyTorch inference stayed behind a compute boundary.
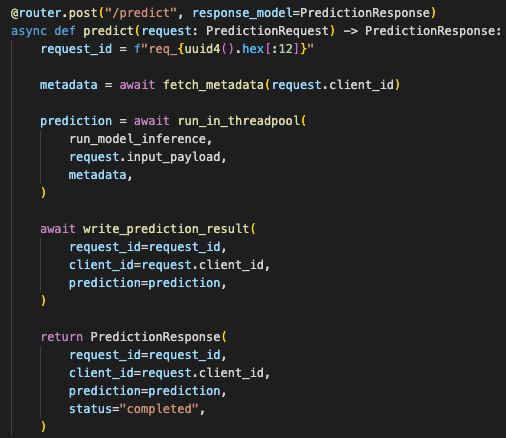
The route validated input, awaited metadata I/O, then called a synchronous inference function through a controlled boundary.
This split made the backend easier to reason about. The database was not waiting behind model execution longer than necessary. The server could keep accepting requests while I/O was pending. The inference function stayed honest as a compute workload instead of pretending to be async.
Request contracts became explicit
FastAPI also cleaned up request contracts.
With Flask, validation had to be added manually. It worked, but it lived beside the route instead of being part of the route contract. With FastAPI and Pydantic, the payload shape became explicit.
For this endpoint, I wanted the request to be boring and typed:
client_id
input_payload
request_timestamp
metadata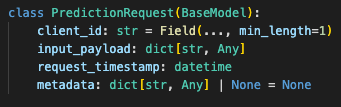
The request contract made malformed payloads fail before they reached the database or model.
If the request was malformed, it failed before it reached the database or the model.
That matters more when the endpoint is under load. Bad requests should be cheap to reject. They should not spend database time, inference time, or logging time before failing.

Invalid payloads stopped at validation, keeping bad requests cheap under load.
The database path became traceable
The database side also got stricter.
I did not want the route to make random queries scattered through the handler. Metadata lookup, result logging, and trace IDs had to be explicit. The API needed to know what it was reading, what it was writing, and which request produced which output.
That gave the route a cleaner backend contract:
- read only the metadata needed
- run inference once
- write the result with request ID
- return the response

The request ID tied input, metadata lookup, inference output, and stored result together.
This helped with debugging too. When a request failed, I could tell whether the failure happened at validation, database lookup, model inference, database write, or response formatting.
Before that, it was too easy to treat the whole endpoint as one block.
Result
Flask had helped me move quickly. FastAPI gave me a better shape for this kind of service: async where the backend waits, synchronous where the model computes, explicit contracts around the payload, cleaner database interactions, and less pressure to fix every spike with bigger hardware.
The endpoint became easier to operate because the request path became clearer.
I/O work stayed I/O-shaped.
Compute work stayed compute-shaped.
The API stopped pretending both were the same.

The final serving path separated async request coordination from synchronous inference and traced the full lifecycle.
This is the lesson I am taking from this build: async is not a performance sticker. It is a design choice. It only helps if the backend knows what kind of work it is doing.
A model-backed API has at least two jobs: coordinate requests and run inference. Those jobs should not be mushed together until the server chokes.
The serving layer decides whether the answer arrives under load without wasting compute.
Onto the next one. Let’s keep sharpening that edge.
First written on April 22, 2019.
Want to implement this architecture in your business?
Discuss Your Project