Queueing and Quantized Llama 2 on Local Hardware
A raw Llama 2 70B serving attempt failed before the first token. The useful version was a quantized local model behind a thin API wrapper, single-worker queue, job records, and validation runs.
Llama 2 has been out for about a week now, and the local AI crowd is moving fast.
There’s a different energy around this release. The model weights are available, commercial use is on the table, and people are already trying to run serious workloads outside hosted APIs. I don’t think that makes cloud models irrelevant. It does make local serving worth testing properly.
The API threw a CUDA out-of-memory error before the first token generated.
That happened while trying to serve Llama 2 70B from a local workstation-style setup.
The model was the wrong size for the hardware in its raw form. FP16 weights are roughly two bytes per parameter. For a 70B model, that puts the weight memory alone around 140GB before runtime overhead, KV cache, batching, or anything else the server needs.
That hardware shape is not casual. You’re in multi-A100 territory if you try to serve the raw model cleanly.
So the question became more practical:
Can a quantized 70B model be served locally in a way that is slow, but stable enough to use for backend experiments?
The goal was local inference for backend experiments
I moved away from the normal Python serving path and tested the llama.cpp route using quantized GGML weights.
The goal wasn’t to build a polished public chatbot. I wanted a local inference service I could put behind an API, run extraction tests against, and avoid paying hosted-token costs for every experiment.
The first working shape looked like this:
client or test script
→ local API wrapper
→ job queue
→ llama.cpp server process
→ generated output
→ result stored with request metadata
The local model sat behind an API wrapper and queue so backend tests could run without treating inference as a normal web request.
Quantization changed the hardware problem
Quantization changed the hardware problem.
Instead of loading FP16 weights, the model weights were compressed into lower precision. The quality tradeoff is real and needs testing, but the storage and memory difference is large enough to change what can even be attempted on local hardware.
For this setup, I treated quantization as an infrastructure decision, not a magic compression trick.
The service needed to track:
- model name
- quantization level
- context length
- prompt template
- max tokens
- temperature
- hardware profile
- tokens per second
- failure reason
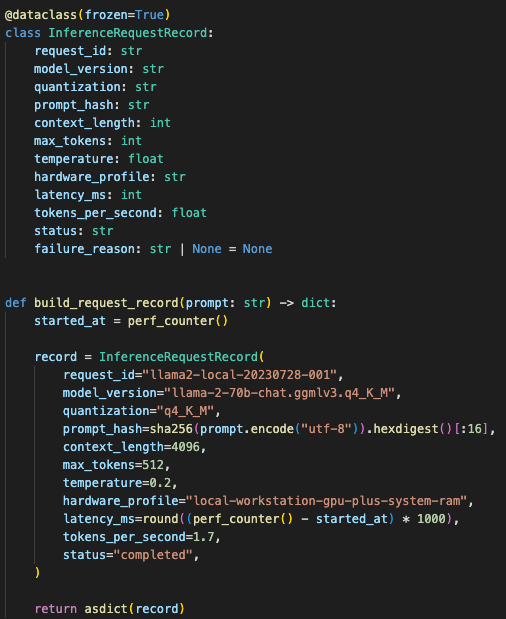
Each local inference job recorded the model version, quantization level, generation settings, runtime behavior, and failure state.
The HTTP layer should not own compute concurrency
The next issue was concurrency.
A normal web server wants to handle multiple requests at once. A local 70B model does not. Even quantized, the model is heavy enough that overlapping generations can push memory, latency, and CPU/GPU scheduling into ugly behavior fast.
So I used the same lesson from image generation: don’t let the HTTP layer decide compute concurrency.
The API accepted requests and placed them into a queue. The inference process handled one job at a time. That made the system slower under load, but it kept the machine alive.
The request path became:
request received
→ prompt validated
→ job created
→ queued for local inference
→ worker sends prompt to llama.cpp
→ output stored
→ caller receives result or polls status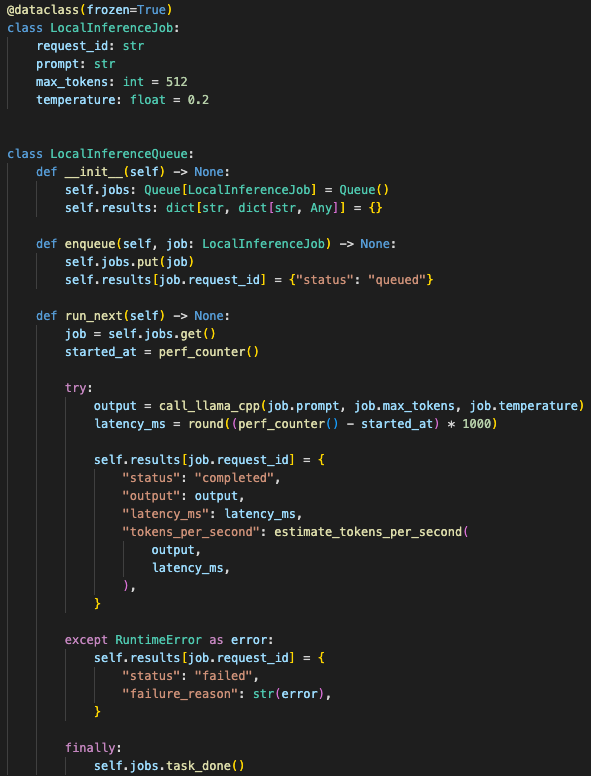
The queue kept local inference stable by limiting concurrency and preserving runtime metadata for each job.
That shape made testing much easier. I could run a batch of extraction prompts overnight without guessing which request caused the machine to fall over. If a prompt failed, the job record had the model version, quantization setting, context size, and error output.
Local serving still needs validation
The output quality still needed strict validation. A quantized 70B model can be useful, but local serving doesn’t remove the need for evals. I had to compare answers against expected extraction fields and watch for failures caused by context length, prompt formatting, or degraded reasoning.
The useful part was control.
Local inference gave me:
- no hosted-token bill for repeated tests
- no rate limit during batch experiments
- full visibility into runtime failures
- direct control over model version and quantization
- a stable target for backend integration tests
It also gave me new operational problems:
- slow cold starts
- large model files
- hardware-specific behavior
- lower throughput
- quantization quality checks
- queue management
- process supervision
- disk and memory pressure
That tradeoff is acceptable for experiments and internal pipelines. I would be more careful before exposing it as a user-facing production endpoint.
Open weights move the infrastructure closer
The main backend lesson is that open weights don’t remove infrastructure work. They move it closer to you.
Hosted APIs hide the model server, hardware, scaling, and runtime limits behind a clean endpoint. Local models expose all of it again: memory layout, quantization, process health, queue depth, throughput, and failure recovery.
For this build, the right shape was boring and controlled. Quantized model. Local server process. Thin API wrapper. Single-worker queue. Job records. Validation runs.
That was enough to make Llama 2 70B usable for backend testing without pretending it behaved like a normal web dependency.
Onto the next one. Let’s keep sharpening that edge.
First written on July 28, 2023.
Want to implement this architecture in your business?
Discuss Your Project