Risk & Compliance AI: Turning Contract Review Into Structured Audit Data
The verification engine turns contract review into structured audit data first, then builds the memo from normalized findings. The model extracts risk fields, while the backend owns parsing, score normalization, report structure, budget controls, and demo-safe input limits.
The first version of the contract review flow had the same problem most legal AI tools have.
It sounded confident before it was structured.
A legal professional I knew wanted to see how AI could fit into their actual review workflow. The use case was not “write me a legal document from scratch.” It was closer to commercial assurance: take a vendor proposal, MSA, contract draft, or commercial terms, then surface the parts that deserve human attention.
That is a different problem.
A chat box can summarize a contract. It can also miss the part that matters.
The risky clause may be buried inside a dense indemnity section. The commercial exposure may sit inside pricing language. The operational problem may be hidden in an uptime promise with no penalty credits.
A model can produce a polished answer while skipping the liability vector.
So I did not want the system to behave like a legal chatbot.
The first useful architecture decision was to split the workflow into two parts:
model extracts structured audit findings
backend builds the memoThat changed the control point.
The audit starts from role and context
The frontend starts with an audit form, not an empty prompt. The user chooses the review perspective:
- Chief Financial Officer
- General Counsel
- Procurement Director
- Chief Information Security Officer
Then they choose the review context:
- Standard Commercial Terms
- Enterprise SaaS / SLA Benchmarks
- GDPR & Data Sovereignty Rules
- Construction & Capital Projects
That input becomes part of the audit boundary. The same document can look different depending on who is reviewing it. A CFO cares about pricing exposure and uncapped fees. General Counsel cares about liability, termination, governing language, and ambiguity. A CISO cares about data handling, breach terms, and security obligations.
The system needed to respect that.
The request flow looked like this:
document text
→ auditor role
→ benchmark context
→ verification endpoint
→ AI gateway
→ structured JSON audit
→ parser and normalization layer
→ Python memo builder
→ executive memo + structured analysis view
The model extracts structured findings. The backend parses, normalizes, and turns those findings into a consistent memo.
The model returns findings, not the final report
The backend service does not ask the model to write the final memo directly.
It asks for a strict JSON object with fields like:
verdict
risk_score
financial_exposure
exposure_matrix
legal_vectors
negotiation_playbook
legal_flags
negotiation_leverage
fallacies
claimsThat is the main control layer.
The model can still reason over the document, but the backend decides what shape the result must take. If the output comes back wrapped in markdown, the service strips the wrapper. If the model returns extra text around the JSON, the parser isolates the first valid JSON object. If the model returns malformed JSON, the system falls into a controlled fallback instead of showing a broken report as if it were reliable.
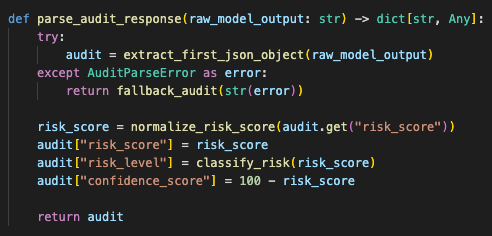
The backend treats model output as untrusted data and only builds a memo after parsing and normalization.
After parsing, the backend normalizes the risk score.
risk_score >= 80 → Critical Risk
risk_score >= 60 → High Risk
risk_score >= 40 → Moderate Risk
else → Low RiskThe UI expects confidence to move in the opposite direction, so the service derives that separately:
confidence_score = 100 - risk_scoreThat sounds small, but it matters. The frontend should not guess how to interpret raw model output. The backend owns that translation.
The memo is deterministic
The report itself is built in Python.
That was intentional.
Legal and commercial review outputs need consistent structure. The memo should not change format every time the model feels creative. The service takes the parsed audit data and builds a fixed markdown memo:
- Executive Verdict
- Financial Exposure Matrix
- Material Legal & Compliance Vectors
- Strategic Negotiation Playbook
The model provides the findings. The backend controls the presentation.
That reduced one of the worst failure modes in AI document review: beautiful, inconsistent prose.
A lawyer or operator does not need a poetic summary. They need to know what the risk is, where the money is exposed, what needs renegotiation, and what should be checked before signing.
The AI gateway owns provider risk
The AI gateway sits in front of the provider call.
That gateway handles the parts a serious AI feature needs before it should be shown to users:
- API key loading
- Model routing
- Budget cap
- Redis spend tracking
- Redis rate limiting
- Provider retries
- Exponential backoff
- Token usage tracking
The provider path currently uses Together AI. The gateway has a model registry for different task types:
reasoning
action
default
vision
fast
codeFor this verification flow, the important part was not the exact model name. It was that the app did not call the provider directly from the frontend. The backend owned the call, the budget, the rate limit, the retry behavior, and the failure response.
That is the difference between a prototype someone can test and a toy that burns money when a user clicks twice.
The gateway also has a hard monthly cap. When Redis is configured, spend is tracked and the budget check can fail closed. Rate limiting uses a per-IP window. Provider failures like 429, 502, 503, and 504 retry with exponential backoff.
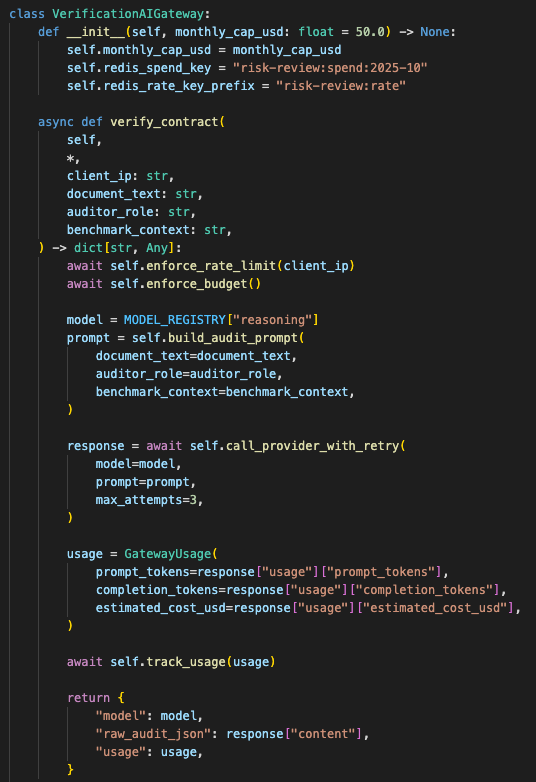
The gateway keeps provider calls, spend tracking, retry behavior, and rate limits outside the frontend.
The frontend blocks fake document ingestion
The frontend has its own boundary work.
The app accepts pasted text and simple text-based uploads:
- .txt
- .md
- .json
- .csv
PDF and Word uploads are intentionally blocked for the demo path. The UI tells the user that OCR needs a dedicated pipeline.
That is the right limitation.
A contract review system should not pretend PDF ingestion is solved just because a file picker exists. Real PDF and Word handling needs extraction, page mapping, formatting preservation, clause segmentation, and source anchoring. Without that, the app can still review pasted text, but it should not claim source-grounded document intelligence.
The report separates memo from audit fields
The frontend output has two views:
Executive Memo
Structured AnalysisThe memo view is print-friendly. It renders the backend markdown into a formal report and supports browser print/export.
The structured analysis view shows audit fields: verdict, risk indicator, model confidence, financial exposure, liability vectors, negotiation points, and blind spots.
That separation is useful. The executive memo is for reading. The structured analysis view is for understanding how the system classified the output.

The UI separates the readable memo from the underlying structured audit data.
The claim has to stay narrow
I also had to be careful with the language around the product.
It is easy for a prototype like this to look more authoritative than it actually is. Legal workflows need source citations, privilege handling, audit trails, redaction, access control, and human review. A polished memo header does not create legal reliability.
The safe claim is narrower and stronger:
This is a structured first-pass commercial risk review engine.
It is not a replacement for legal judgment.
That is still valuable.
The real engineering win was moving from freeform generation to controlled audit data.
A weaker version would do this:
contract text
→ LLM
→ legal-sounding memoThis version does more work around the model:
contract text
→ role/context selection
→ backend gateway
→ structured JSON audit
→ parser and normalization
→ deterministic memo builder
→ report + structured analysis viewThe next hardening step is clause-level anchoring
The next version should go deeper.
The obvious production hardening path is clause-level anchoring:
document upload
→ text extraction
→ clause segmentation
→ clause IDs
→ per-clause audit
→ exact quote validation
→ source-linked risk flags
→ attorney review queueThat is where the system becomes more defensible.
A high-risk finding should point to the exact clause text. If the model cannot quote the offending language, the flag should stay in review instead of appearing as verified. If the document came from a PDF, the system should preserve page number and clause location. If a lawyer edits the result, the app should store that correction as review data.
That is the direction I would take this.
For now, this prototype establishes the first control layer: role-aware review, provider isolation through a gateway, structured JSON findings, backend-owned memo generation, and a frontend that separates polished output from the underlying risk fields.
That is already a better pattern than asking a model to “review this contract” and trusting whatever comes back.
Risk and compliance work cannot depend on AI prose alone. The system needs structure around the model: what it extracts, how it is parsed, how risk is normalized, how output is formatted, and what still requires human review.
Onto the next one. Let’s keep sharpening that edge!
First written on October 28, 2025.
Want to implement this architecture in your business?
Discuss Your Project