Server-Side Session Memory for LLM Support Interfaces
An LLM support interface forgot user context because the model API was stateless. The fix was server-side session memory with Redis, durable PostgreSQL audit history, backend-owned prompt assembly, and clear fallback behavior.
I’ve been spending more time with language model APIs lately, mostly around support workflows. The strange thing is they feel conversational on the surface, but the infrastructure underneath is still plain HTTP. That gap creates problems fast once users expect the system to remember what they just said.
The model forgot the user’s name on the third turn.
That sounds like a model problem at first. In the actual system, it was a state problem.
I was working on a specialized support interface using text-davinci-002. The goal was simple enough: let a user ask a question, follow up naturally, and get support answers without restarting the whole context every turn.
The API didn’t work like that by default.
Each request was stateless. You send a prompt, the model returns text, and the request ends. On the next message, the model has no memory unless the application sends the previous context again.
That makes LLM chat feel strange from a backend perspective. The model looks conversational, but the API behaves like a normal stateless text endpoint.
Client-owned history was the wrong boundary
Early implementations around this problem are messy right now. A common pattern is to keep the conversation history in the browser, then have the frontend concatenate the full chat and send it back with every new message.
That is convenient, but it puts too much control in the wrong place.
If the frontend owns the history, the user can change the history.
A user can edit the payload before it reaches the backend. They can inject fake prior turns, remove inconvenient context, or add instructions that were never actually said. Then the backend passes that assembled prompt to the model as if it were trusted application state.
For a support interface, that is a bad boundary.
The user should be able to send a new message.
They should not be able to author the system’s memory.
I moved memory server-side
I rebuilt the flow around server-side session memory.
New request shape:
client sends message
→ API receives session ID and user text
→ backend loads trusted history from Redis
→ backend assembles the prompt
→ model generates response
→ backend stores the new exchange
→ response returns to client
→ audit record writes to PostgreSQL
The client sent only the latest message. Redis held short-term trusted memory. PostgreSQL kept the durable audit trail.
The frontend became much simpler. It only sent two things:
- session ID
- latest user message
The backend owned everything else.
When the user connected, the API created a secure session ID. Redis stored the short-term conversation state under that ID. On each request, the FastAPI endpoint loaded the last few turns, formatted them into a controlled context block, appended the new message, and sent the final prompt to the model.
After the model returned a response, the backend wrote the new exchange back to Redis. A separate write persisted the interaction to PostgreSQL for audit and later review.
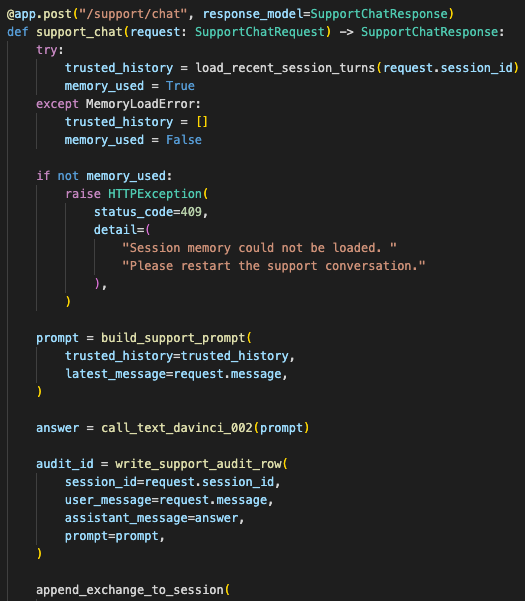
The handler loaded trusted context server-side, assembled the prompt, called the model, then wrote short-term memory and durable audit state.
The backend owned prompt assembly
That gave the system a cleaner contract:
- the client owns the latest user message
- Redis owns short-term session memory
- PostgreSQL owns durable audit history
- the backend owns prompt assembly
- the model only sees context created by the server
This also made the context window easier to control. The backend could cap history to the last ten turns, remove unsafe fields, trim long messages, and apply formatting rules before the prompt ever reached the model.
The Redis structure needed real rules, not just a dump of chat messages.
Each session needed:
- session key format
- TTL for inactive sessions
- max turn count
- max token estimate
- role labels
- message timestamps
- audit ID reference
- safe fallback when memory cannot be loaded
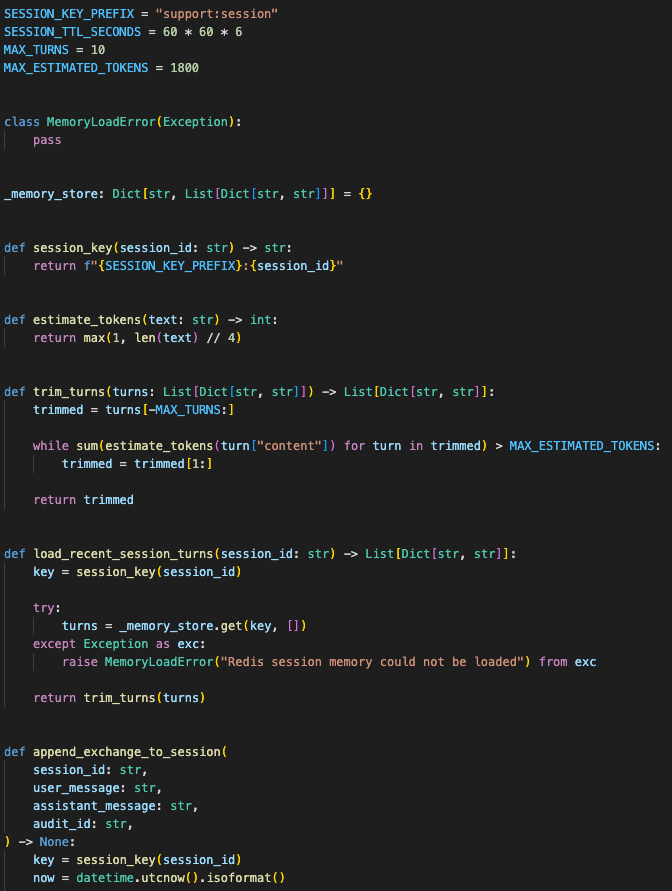
The memory record had expiry, turn limits, role labels, token estimates, audit references, and a safe fallback path.
The Redis failure path mattered. If memory could not be loaded, the API needed to degrade cleanly instead of silently pretending it remembered the conversation. For support, a clean reset with a clear message is safer than building a response from partial or missing state.
Result
This architecture didn’t make the model truly remember anything. It made the application responsible for memory.
That is the right place for it.
LLM context behaves like a backend session. The same old rules still apply: don’t trust client-owned state, keep server-side records authoritative, limit what gets stored, expire what should not live forever, and write audit trails for sensitive workflows.
The model can generate the next response. The application has to decide what history it is allowed to see.
Onto the next one. Let’s keep sharpening that edge.
First written on June 14, 2022.
Want to implement this architecture in your business?
Discuss Your Project