Streaming Architecture for Sensitive Text Generation Workloads
A text generation endpoint hit a gateway timeout while the instance kept burning compute. The fix was a Server-Sent Events lifecycle with validation, controlled streaming, disconnect cancellation, frontend buffering, and safe operational logging.
The first failure was a thirty-second timeout.
A user submitted a prompt for a generated product description. The backend accepted it, passed it into the generation service, and waited for the complete text before returning a response.
Nginx closed the connection before the model finished.
The frontend showed a 504 Gateway Timeout. The instance kept generating in the background. That meant compute was still running after the user had already received a failed page.
For a normal classification API, the old request path was fine:
client
→ API
→ validation
→ inference
→ JSON responseThose requests were short and predictable. Text generation had a wider runtime range. A short output could finish quickly. A longer one could cross gateway, browser, or app-server timeout limits.
The issue became sharper because the prompts and outputs could contain sensitive commercial data: product details, internal notes, pricing language, supplier terms, and draft copy that wasn’t meant to leak into logs or failed retry paths.
So the architecture had to handle three things at the same time:
- long-running generation
- safe cancellation
- controlled visibility of partial output
The endpoint became a stream
I moved the endpoint away from a single blocking response and rebuilt it around Server-Sent Events.
New flow:
client submits prompt
→ API validates and redacts unsafe fields
→ generation worker starts
→ backend streams chunks
→ frontend buffers and renders partial output
→ stream closes, fails, or cancels cleanly
The request lifecycle moved from a blocking JSON response to a managed stream with cancellation and controlled partial output.
The API contract changed from “return the final text” to “manage a stream.”
That forced a clearer lifecycle:
- request accepted
- generation started
- chunk emitted
- client disconnected
- generation cancelled
- generation completed
- error returned without dumping sensitive payloads
Cancellation became part of the backend contract
The cancellation path was the main backend fix. If the client disconnected, the worker checked the connection state and stopped generating. That prevented the instance from burning compute on a response nobody would receive.
The frontend also needed a safer update path. Streaming many small chunks directly into React state created too many renders. I buffered chunks and rendered at a controlled interval, so the user saw progress quickly without turning the browser into part of the bottleneck.
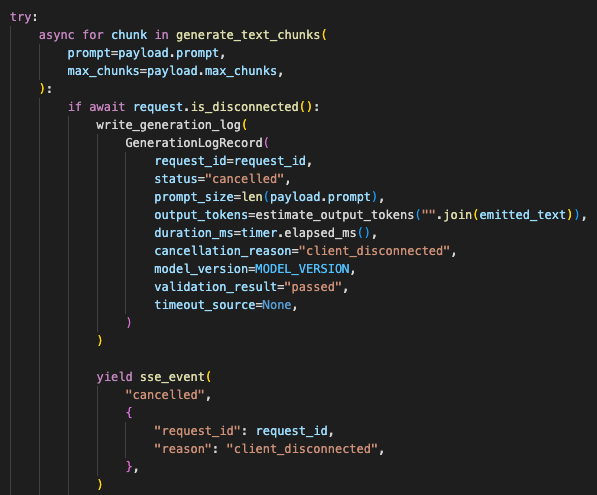
The endpoint validated the request, streamed chunks, checked disconnect state, and emitted controlled error events without leaking payload contents.
Logs kept operational shape, not sensitive text
The logs had to change too. The service could not casually log full prompts or generated text. I kept operational fields instead:
- request ID
- prompt size
- output token count
- generation duration
- cancellation reason
- model version
- validation result
- timeout source
That gave enough visibility to debug the system without storing sensitive content in application logs.
Result
After the change, users started seeing output almost immediately. Long generations no longer died as silent 504 failures. Disconnected clients stopped consuming worker time. Failed requests returned controlled stream events instead of broken pages.
The model didn’t need to be treated as a special magical component. It behaved like any other slow backend workload: validate the input, control the request lifecycle, stream progress, cancel abandoned work, avoid leaking sensitive data, and log the operational shape without storing the payload.
For text generation, the serving architecture matters as much as the model call. A normal REST endpoint can hide too much: timeouts, wasted compute, unsafe logs, bad retries, and unclear failure states.
The streaming boundary made those failure modes visible enough to manage.
Onto the next one. Let’s keep sharpening that edge.
First written on December 02, 2021.
Want to implement this architecture in your business?
Discuss Your Project