Supervisor Agents: Enforcing Deterministic State Across Multi-Agent Workflows
Multi-agent workflows fail when model calls mutate shared state directly. A supervisor layer keeps state transitions, tool access, retries, and audit logs deterministic enough to debug.
The first multi-agent workflow broke in a very predictable way.
Two agents updated the same task state from different assumptions.
One agent marked the step complete because it had drafted the output. Another agent reopened the same step because its validation pass found missing fields.
The UI showed progress.
The backend had conflicting state.
The task was effectively completed and blocked at the same time. The final response was ready, but the review artifact still had unresolved validation errors.
That is where I stopped treating the agents like a “team” and started treating them like distributed workers with unsafe write access.
By April 2026, multi-agent systems were everywhere in the AI conversation. Coding agents, research agents, planner agents, reviewer agents, browser agents, deployment agents, customer support agents. The language around them made everything sound independent and collaborative.
That wording is dangerous once the workflow can mutate state.
A production system cannot let independent model calls update shared records just because they have different role names.
The backend still needs one owner of truth.
The model can reason, the agent can propose, and the tool can execute. The write still needs to pass through a deterministic layer that knows the current state, the allowed transition, and the agent’s scope.
That became the point of the supervisor.
In practice, the supervisor was less of a manager persona and more of a control layer around state transitions, tool access, retries, and audit logs.
The first workflow had unsafe shared state
The first rough workflow looked like this:
user request
→ planner agent
→ researcher agent
→ implementation agent
→ reviewer agent
→ final responseIt looked clean on paper.
The issue appeared when the workflow needed memory.
task status
selected files
intermediate findings
tool outputs
validation errors
retry count
approval state
final artifactAll of that became shared state.
Once multiple agents could read and write that state, the workflow started behaving less like a chat chain and more like a distributed system with race conditions.
The architecture needed a stricter shape:
user request
→ API endpoint
→ supervisor service
→ task record
→ queue
→ bounded agent worker
→ tool permission check
→ state transition validator
→ event log
→ next task dispatch
→ final response
The supervisor owns the workflow state. The agents work against it.
That was the main boundary.
Agents propose. The supervisor commits.
Agents can return structured proposals:
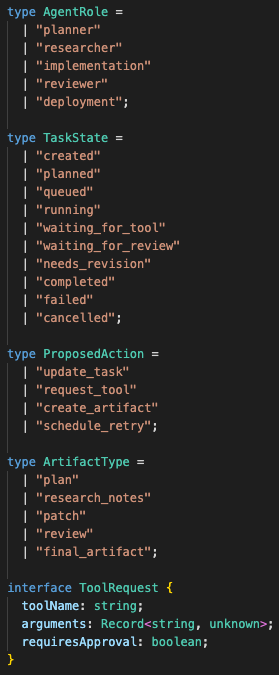
An agent can propose a state update, but it does not write directly to the database.
For example:
action: update_task
target_step: validate_requirements
status: needs_revision
reason: missing acceptance criteria
artifacts: [...]But they do not write directly to the database.
The supervisor receives the proposal, checks the current state, checks the transition rules, verifies the agent’s scope, and only then commits the update.
That check caught the behavior I cared about most: a worker returning late and trying to write against a task state that had already moved on.
Without that boundary, the stale result would have looked like a valid update.
The system also needed clean answers to basic workflow questions:
- Can this agent close the task?
- Can this agent call the deployment tool?
- Can this agent overwrite another agent’s output?
- Can this step move from failed back to running?
- Can a validation agent create implementation changes?
- Can a retry reuse previous tool output?
- Can two branches merge into the same final artifact?
Those are backend questions.
A prompt can describe the desired behavior, but the backend has to enforce it.
The state machine became the useful part
A task could move through a controlled set of states:
created
→ planned
→ queued
→ running
→ waiting_for_tool
→ waiting_for_review
→ needs_revision
→ completed
→ failed
→ cancelled
The workflow does not need to be rigid. It needs to reject impossible states.
A task should not be completed and waiting for review at the same time.
A cancelled task should not keep executing tool calls.
A failed validation step should not allow a final answer to be published.
A worker retry should not duplicate a database write.
A browser agent should not gain file-system privileges because the planner asked for it.
At that point, the agent layer was no longer the hardest part. The hard part was normal backend control: task records, queues, idempotency, tool permissions, state transition rules, event logs, retry policy, and cancellation.
The queue boundary kept failures contained
The queue boundary mattered early.
The supervisor should not call every agent inline inside one HTTP request. That makes the whole workflow fragile. A long-running agent can hit route timeouts, provider latency, browser cancellation, worker crashes, or deployment limits.
The safer version is:
API accepts the request
supervisor creates a task record
queue dispatches bounded work
worker runs one agent step
worker returns structured output
supervisor validates transition
next step is queued
user polls or streams progress
Each worker runs a bounded step, returns structured output, and lets the supervisor decide the next transition.
That shape gives the system room to fail.
If the reviewer agent times out, the whole workflow does not disappear.
If the implementation worker crashes, the task can remain in running until a timeout monitor marks it stale.
If the user cancels, the supervisor can mark the task cancelled and future workers can refuse to commit writes.
If a provider returns malformed JSON, the transition validator can reject the update and move the task into needs_revision or failed.
The workflow becomes observable.
It also keeps retries smaller. A failed reviewer step can be retried without replaying the planner, researcher, and implementation steps from zero.
That matters for cost and latency. A multi-agent workflow can burn a lot of tokens if every failure restarts the entire chain.
The production question is what happens when step four fails after steps one, two, and three already wrote state.
- Do you retry only step four?
- Do you replay from the beginning?
- Do you preserve the planner’s output?
- Do you delete partial artifacts?
- Do you notify the user?
- Do you let another agent repair the failure?
- Do you block the final response?
Those decisions need to exist outside the model.
The event log became the durable memory
The event log helped.
Every meaningful state change should produce an event:
task.created
plan.generated
step.queued
agent.started
tool.requested
tool.approved
tool.rejected
agent.output_received
state.transition_accepted
state.transition_rejected
step.retry_scheduled
task.cancelled
task.completed
task.failed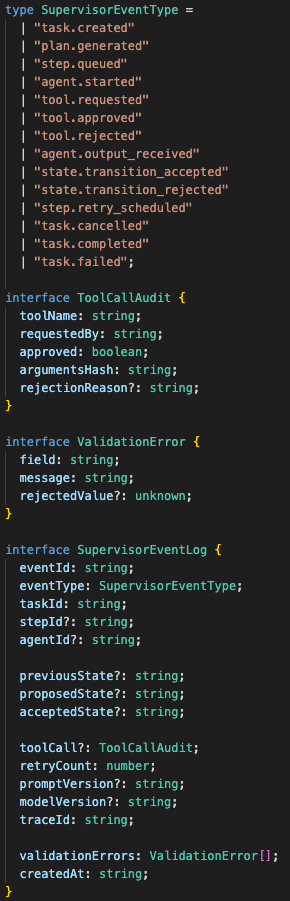
The event log gives the workflow memory that is separate from the model’s memory.
That matters because model memory is not enough. A model can summarize what happened, but the system needs a durable record of what actually happened.
The supervisor needs to know:
- Which agent ran
- What prompt version it used
- What model version it used
- Which tool it requested
- What arguments it sent
- What state it saw
- What state it tried to write
- Whether the write was accepted
- Why a transition was rejected
- How many retries happened
Without that, debugging becomes theatre.
You ask the agent what happened.
The agent explains something plausible.
The database says something else.
I don’t want production systems where the only audit trail is another model-generated summary.
Tool access cannot be implied by the agent name
Tool access needed the same treatment.
Agents should not all share the same tool belt.
A planner can decompose work.
A researcher can read documents.
An implementation agent can propose file changes.
A reviewer can validate output.
A deployment agent, if it exists at all, should have a separate approval path.
Those boundaries should be enforced by the backend, not implied by the agent name.
The tool permission check looked like this:
agent role
→ requested tool
→ task state
→ tenant/project scope
→ approval requirement
→ argument validation
→ execution policy
→ tool call log
Tool access is a backend decision tied to role, state, scope, approval requirements, and validated arguments.
That prevents a common failure path.
The planner decides deployment is the next step.
The implementation agent asks for a deployment tool.
The reviewer has not passed yet.
The backend rejects the tool call because the task is still in waiting_for_review.
That rejection should be a normal rule, not a hope that the model behaves.
The same applies to file writes.
An agent can propose a patch. The supervisor can validate file paths, allowed directories, branch state, diff size, and test requirements before allowing the write.
For example:
- No writes outside the project root
- No environment file changes without approval
- No package install without review
- No migration without rollback note
- No production deployment from an unvalidated task
- No final response if required checks failed
These are system rules, and the agents operate inside them.
Workers need a consistent state snapshot
The hardest part was shared state.
If every agent receives a slightly different version of the task, the workflow drifts.
The planner thinks the goal is one thing.
The researcher finds evidence for a narrower version.
The implementation agent acts on an older plan.
The reviewer validates against a newer requirement.
Now the system has five plausible histories and one database row.
The supervisor has to control what state each worker receives.
A worker should get a snapshot:
task ID
current state
assigned step
allowed tools
input artifacts
required output schema
deadline
retry count
model config
trace IDThe worker returns a proposal.
The supervisor checks whether the task is still in the expected state before accepting it.
If the task changed while the worker was running, the supervisor can reject the stale write.
That is basic distributed systems hygiene.
It applies even when the workers are AI agents.
Especially then.
Schema validation has to be stricter than the prompt
The validation layer also needs to be stricter than the prompt.
A prompt can say:
Return valid JSON.The backend still has to assume the model may return markdown, commentary, partial JSON, old schema fields, or a malformed tool request.
So the supervisor needs schema validation at the boundary.
Agent output should be parsed into a known shape:
agent_id
task_id
step_id
proposed_action
proposed_state
confidence
artifacts
tool_requests
validation_notes
blocking_issuesIf the output does not fit, the system should not guess too much.
It can ask for repair.
It can retry with a stricter prompt.
It can mark the step as failed.
It can route to human review.
What it should not do is silently write ambiguous model output into workflow state.
That is how agent systems become unreliable without looking broken.
Parallel agents need separate artifacts
Concurrency created another edge case.
Parallel agents are tempting.
Run research, code inspection, dependency analysis, and test planning at the same time. Save time. Merge the outputs later.
That can work, but only if the merge is controlled.
Parallel branches should write to separate artifacts first:
research_notes
code_findings
dependency_risks
test_plan
review_notesThe supervisor can then run a merge step that produces the next canonical artifact.
The branches should not all overwrite current_plan.
Shared mutable state is the dangerous part.
Separate artifacts make the merge visible.

Parallel agents should write separate artifacts first, then let the supervisor merge them into a canonical plan.
That one design choice reduces a lot of weird behavior.
If the researcher finds something useful, it does not overwrite the implementation plan.
If the reviewer disagrees, it produces a review artifact instead of mutating the task directly.
If the merge fails, the system knows which artifact caused the conflict.
The pattern is old backend discipline applied to a newer worker type.
The contract is the product
The model layer can still be useful.
The planner can reason through ambiguous requests.
The researcher can search and summarize.
The implementation agent can draft code changes.
The reviewer can find gaps.
But each one should operate inside a bounded contract:
agent role
allowed inputs
allowed tools
expected output schema
maximum runtime
retry policy
state transition limits
audit loggingThat contract is the product.
The prompt is only one part of it.
For a founder or operator, this matters because agent systems fail expensively when they get partial autonomy wrong.
A chatbot can give a bad answer and the user can ignore it.
An agent workflow can write files, update records, send messages, call APIs, create tickets, trigger jobs, or burn provider spend while appearing productive.
That changes the risk profile.
The more autonomy the system has, the more deterministic the backend has to be around it.
I would rather ship a smaller agent workflow with strict state control than a dramatic multi-agent demo that cannot explain its own writes.
The useful version is a supervised workflow:
- One owner of state
- Bounded agent workers
- Queue-backed execution
- Tool permissions
- Schema validation
- Event logs
- Idempotent writes
- Retry policy
- Cancellation handling
- Human approval for dangerous actions
- Clear rollback path

The agents can be flexible inside their lane. The system around them should be boring enough to debug.
The supervisor pattern is useful because it gives the backend a place to say no.
No, that transition is invalid.
No, that tool is not allowed in this state.
No, that worker result is stale.
No, that output does not match the schema.
No, that task was cancelled.
No, that deployment needs approval.
That is what keeps the workflow from turning into a pile of confident model calls fighting over shared state.
Agent autonomy is useful when the boundaries are real.
The supervisor pattern gives the backend one place to control state, reject stale writes, enforce tool permissions, record events, and stop the workflow when the system is no longer safe to continue.
That is the version I trust more.
The agents can still reason, inspect, draft, and review. The workflow survives because state changes pass through a layer that is deterministic enough to debug when one of them is wrong, late, malformed, overconfident, or acting outside its lane.
Onto the next one. Let’s keep sharpening that edge!
First written on April 08, 2026.
Want to implement this architecture in your business?
Discuss Your Project