Surviving Spot Interruptions: Decoupling PyTorch Inference on AWS
A PyTorch inference API was tied directly to an interruptible GPU instance. The fix was splitting stable request handling from Spot-backed compute with SQS, job IDs, retryable workers, result storage, and a status endpoint.
I ran into a simple infrastructure problem this week: the expensive machine was also the fragile machine.
I was working with a PyTorch inference setup that needed heavier compute than a normal CPU web server. Running that workload all day on an on-demand GPU instance gets expensive fast, especially for a small team trying to improve an internal workflow without turning the infrastructure bill into the project.
AWS Spot instances looked like the practical option.
Cheaper compute. Same workload. Big catch: AWS can take the instance back.
That only works if the system is built around that reality.
Mine was not, at first.
The existing version was too direct:
client request
→ API endpoint
→ GPU instance runs PyTorch
→ response returns to client
The user-facing request stayed tied to a GPU machine that could disappear during processing.
It worked while the instance stayed alive.
That condition was too weak.
If the GPU instance disappeared during a request, the user had a bad experience. The request could hang, fail, or return an upstream error. The model was fine. The coupling was the problem.
I had tied the user-facing request path to temporary hardware.
Wrong shape.
A web request wants a fast, stable answer. A GPU job wants time, memory, and hardware that might disappear if it is running on Spot. Those two things should not be welded together.
I split stable API work from unstable compute
So I split the system.
The API layer stayed on stable, boring compute. Its job was to accept the request, validate it, create a job, and return a job ID.
The heavier inference work moved behind a queue.
New shape:
client request
→ API validates payload
→ API writes job to queue
→ API returns job ID
→ worker picks up job
→ PyTorch runs inference
→ worker stores result
→ client checks job status
The queue separated the stable request path from the interruptible GPU worker path.
This was the main change.
The API stopped forcing inference to finish inside the original HTTP request. The frontend no longer held an open connection to a compute worker that could disappear mid-run.
SQS became the buffer
For the queue, I used SQS.
I needed a managed queue that could hold jobs while workers came and went. I did not want to build a custom job system just to rediscover queue edge cases the hard way.
The API became a small job creator:
receive request
validate payload
create job_id
send message to SQS
return job_id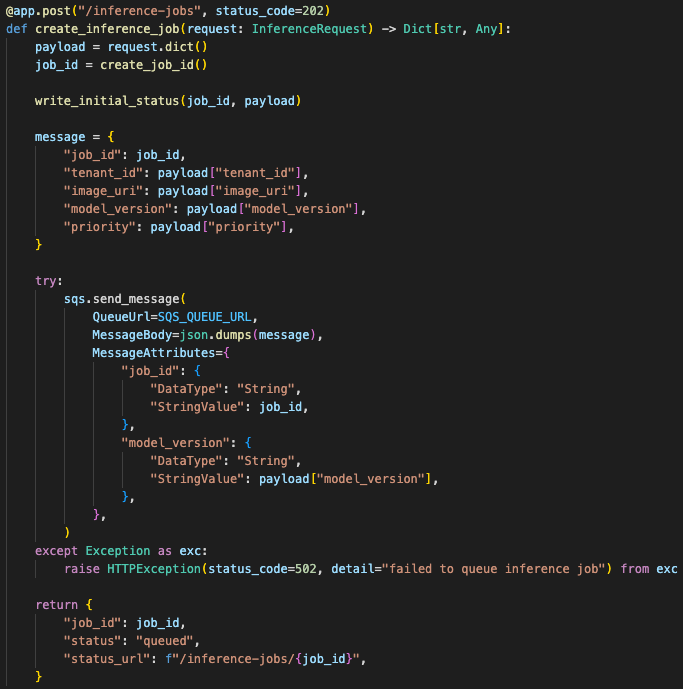
The API validated input, created a job ID, queued the payload, and returned quickly.
The worker became a separate process:
poll SQS
receive job
run PyTorch inference
write result to cache/storage
acknowledge message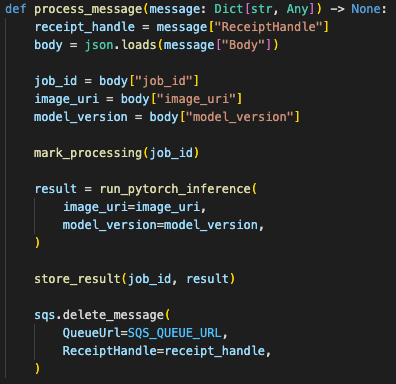
The worker deleted the queue message only after inference completed and the result had been stored safely.
The worker should only remove the message from the queue after the result has been written somewhere safe.
If the worker dies halfway through inference, the job should return to the queue instead of disappearing.
This is where SQS helped. A message becomes temporarily invisible while one worker is processing it. If the worker finishes, it deletes the message. If the worker dies and never deletes it, the message becomes visible again after the visibility timeout.
Another worker can pick it up.

Visibility timeout turned worker interruption into retryable work instead of a lost request.
This still needs sane timeouts, idempotent workers, and result checks.
If the same job runs twice, the system should not corrupt state. If the result already exists for a job ID, the worker should avoid writing a conflicting result. If a job keeps failing, it should move to a dead-letter path instead of looping forever.
I kept the first version modest:
- stable API server
- SQS queue
- GPU worker process
- result cache
- job status endpoint
- basic retry behavior

The API stayed available while GPU workers could fail, retry, recover, or be replaced.
The frontend waited on job state, not the worker
The frontend behavior changed too.
Instead of waiting for the final answer in the same request, it received a job ID quickly. Then it checked status:
queued
processing
complete
failed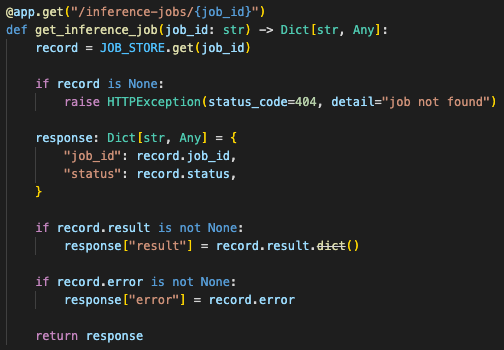
The frontend tracked durable job state instead of holding an open request to interruptible compute.
That small change made the user-facing side less brittle.
If the GPU worker was busy, the user waited.
If a Spot instance disappeared, the job could be retried.
If the queue had a backlog, the API could still accept requests instead of collapsing with the worker.
At the end, the backend had a cleaner contract.
API layer:
validate request
create job
return job ID
expose statusWorker layer:
consume job
run inference
store result
acknowledge only after success
The queue made the boundary explicit: stable API for user-facing work, interruptible GPU workers for heavy inference.
Result
This was the useful AWS lesson for me.
I do not need to be fancy to get value from cloud primitives.
Use stable compute where stability matters. Use cheaper interruptible compute where interruption is acceptable. Put a queue between them so one layer does not take down the other.
The app should not fail just because the worker machine is temporary.
Spot compute can be useful, but the system has to assume it can vanish. If the API waits directly on that worker, Spot is a gamble. If the work is queued, retryable, and tracked by job ID, Spot becomes much easier to tolerate.
Do not let unstable compute sit inside the user-facing request path.
Once I made that change, the system became easier to operate. The API stayed boring. The worker could fail and recover. The queue became the buffer. The result store became the handoff point.
Onto the next one. Let’s keep sharpening that edge.
First written on August 30, 2019.
Want to implement this architecture in your business?
Discuss Your Project