The 10M Token Trap: Why Infinite Context Windows Do Not Replace Data Engineering
Large context windows do not remove the need for source selection, freshness checks, permission boundaries, token budgets, and audit logs. They make weak data engineering harder to see.
The first long-context test did not fail because the model ran out of space.
It failed because the system had no clean rule for what deserved to enter the prompt.
I was testing a document-heavy AI workflow where the easy version was obvious: pass more files into the model and let the larger context window absorb the mess. Policies, notes, exported tickets, generated summaries, old drafts, copied markdown, whatever the user had available.
The model could take more context now.
So the temptation was simple.
Upload everything.
Let the model read it.
Ask the question.
Get the answer.
That approach feels productive during a demo because it removes the annoying parts: chunking, indexing, metadata, retrieval, file normalization, access control, freshness checks, source ranking, and data contracts.
It also moves too much responsibility into the model call.
By this point, million-token context windows were already part of the AI landscape. Some models were being advertised with context windows large enough to swallow whole repositories, long contracts, exported chat histories, and large internal document sets in one request.
That sounds like the end of retrieval.
It isn’t.
The failure was source selection
The first version I tested was too generous.
It treated available context like useful context. If the user asked a broad question, the system pulled too many files, kept duplicate boilerplate, and sent old versions beside newer ones. The model still produced a confident answer, which made the failure harder to spot.
A visible refusal would have been easier to debug.
A polished answer built from dirty source selection is worse.
The issue was not whether the model could read a lot of text. It could. The issue was whether the backend could explain why that text was selected, whether it was current, whether the user had permission to see it, and whether the request was worth the cost.
That pushed the architecture back toward a controlled data pipeline.
The request flow I wanted looked more like this:
user question
→ API endpoint
→ tenant and permission check
→ query classifier
→ document registry lookup
→ metadata filter
→ retrieval index
→ context packer
→ token budget check
→ model call
→ answer with source trace
→ logs for cost, latency, and selected documents
The context window is only one part of the system. The more important part is deciding what enters the window.
A 10M-token model can accept a large input, but that does not mean every input deserves to be sent. Old files, duplicated exports, stale markdown, broken PDFs, archived tickets, old meeting notes, and copied Slack threads can all fit inside a giant window.
That does not make them useful.
It makes the source-selection failure harder to see.
With a smaller context window, the system is forced to choose. The constraint is annoying, but it makes the architecture honest. You need retrieval. You need metadata. You need source ranking. You need a clear rule for what gets included and what gets dropped.
With a massive context window, the system can hide bad engineering behind a larger prompt until the wrong answer becomes expensive to debug.
The backend still needs an ingestion path
For a serious AI workflow, documents should not move straight from upload to prompt. They need to pass through a controlled pipeline:
file upload
→ object storage
→ file type detection
→ text extraction
→ section parsing
→ metadata extraction
→ document versioning
→ chunking or section indexing
→ embedding/index update
→ retrieval-ready document registry
The registry keeps raw files, parsed content, metadata, permissions, versions, and processing status out of the prompt layer.
The registry is the part that is easy to skip in a prototype.
I don’t think it can be skipped once the system touches real business documents.
A prompt cannot be the source of truth for company knowledge. The backend needs to know what document was used, which version was selected, when it was indexed, who can access it, and whether it has been superseded.
Otherwise, the model can answer from an old policy and nobody knows until someone acts on it.
That is a production failure.
I also wanted the system to separate document storage from context assembly.
Object storage keeps the raw files.
The database keeps document records, permissions, version IDs, metadata, and processing status.
The retrieval index supports search and ranking.
The context packer builds the final model input.
Those are separate jobs.
When they collapse into one “send everything to the model” step, debugging gets ugly. If the answer is wrong, you cannot easily tell whether the wrong document was uploaded, the parser failed, the index missed the right section, the context packer included stale content, or the model ignored the relevant paragraph.
A long-context model does not remove those failure modes.
It lets more of them happen inside one huge request.
The context packer became the control point
Its job is not to fill the window. Its job is to spend the token budget well.
The rules were simple enough:
- Include high-confidence sources first
- Prefer current versions over archived versions
- Keep section boundaries intact
- Preserve document IDs
- Deduplicate repeated content
- Drop low-value boilerplate
- Reserve space for the user question and instructions
- Cap per-source token usage
- Log what was included and why
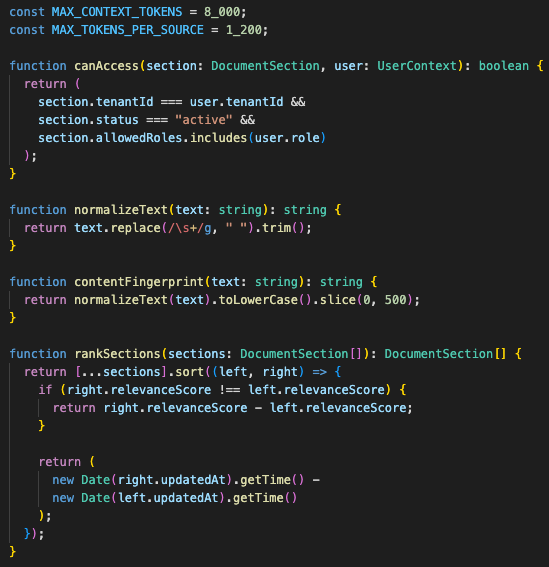
The context packer should emit selected document IDs and section IDs so the answer can be traced back to its source material.
The logging part matters.
If the system cannot explain what it sent to the model, it cannot explain why the answer came out that way.
For internal tools, this is already important.
For legal, medical, finance, education, compliance, or sales operations, it becomes non-negotiable. The user needs to know which source the answer came from. The operator needs to know whether the answer used approved material. The developer needs to know whether the retrieval layer selected the right evidence.
Freshness belongs outside the model
Freshness was the next ugly part.
Long context makes it tempting to keep a giant project memory around. That sounds convenient until the business changes.
A price changes.
A contract gets amended.
A policy gets replaced.
A customer’s implementation status moves.
A cached summary points to an older document version.
Now the AI system is answering from stale memory while sounding completely normal.
Freshness needs to live outside the model.
The backend should know which files are active, which ones are archived, which ones are drafts, which ones require review, and which ones are expired. The model should receive selected context only after those decisions have already been made.
The model should not be the freshness engine.
Permissions have to run before context assembly
Access control has the same shape.
A large context window can hold an entire workspace. That is dangerous if the system does not enforce permissions before context assembly.
The check has to happen before retrieval results become prompt text.
tenant ID
user role
document ACL
folder permission
project membership
sensitivity tag
allowed source typeThose checks belong in the backend.
If a user asks a question about a project, the retrieval layer should only search documents that user can access. The context packer should only assemble approved sections. The model should never see restricted text and then be instructed to “not reveal it.”
That is too late.
Once restricted content enters the model input, the boundary has already failed.
The runtime path still needs protection
Then came the runtime problem.
On a hosted API path, the constraint is not only token count. The request has to survive frontend timeout behavior, serverless execution limits, provider latency, user retries, and cancellation.
A long-context call can take long enough for the user to refresh the page.
A browser can retry.
A frontend can trigger a second request because the first one looked stuck.
A serverless route can approach its execution limit while the provider is still processing.
If the system does not use request IDs, cancellation handling, token caps, and idempotency checks, it can double-spend tokens before the user ever sees an answer.
That kind of failure is easy to miss in a clean demo.
It shows up when the system is slow, the user is impatient, and the provider call is expensive.
The API boundary has to protect the workflow before the model call starts:
- Request size limits
- Maximum context budget
- Per-source caps
- Timeout settings
- Provider retry limits
- Cancellation handling
- Idempotency keys
- Rate limits per tenant
- Fallback response when context assembly fails
Those controls are not decorative. They stop one broad question from becoming a slow and expensive incident.
Long-context systems need better logs
A normal API call can be logged with route, status code, duration, and error.
An AI request needs more detail:
- Model used
- Input tokens
- Output tokens
- Retrieved document IDs
- Selected section IDs
- Context size
- Latency by stage
- Provider latency
- Cache hit or miss
- Validation errors
- Fallback path used
- Answer source coverage
Without those logs, long-context systems become expensive black boxes.
The user says the answer is wrong.
The developer checks the model response.
The model response looks plausible.
Nobody knows what documents were included.
Nobody knows whether the correct source was retrieved.
Nobody knows whether the context window was packed with repeated junk.
Nobody knows whether the answer used stale material.
The model call is only the visible part.
The backend has to make the request explainable enough to debug.
Summaries are another artifact, not a shortcut
I also do not trust “just summarize everything first” as the default answer.
Summaries are useful, but they are lossy. A summary pipeline needs its own versioning and source traceability.
If a 200-page contract becomes a 2-page summary, the system should know:
- Which contract version was summarized
- Which model generated the summary
- When it was generated
- Which sections were compressed
- Whether a human approved it
- Whether the source document changed afterward
Otherwise, the summary becomes another stale artifact.
That is how AI systems quietly rot.
The better pattern is layered context.
raw document in object storage
→ parsed sections in the database
→ embeddings or search index for retrieval
→ optional summaries with version metadata
→ request-time context packer
→ model answer with source trace
→ audit logs
Each layer has a job. Each layer can be inspected. Each layer can be replaced without changing the entire workflow.
The business risk is cost, trust, and traceability
The business value is not “we can send 10M tokens.”
The business value is that the system can answer from the right material, with bounded cost, controlled access, observable behavior, and enough traceability to fix mistakes.
That matters more than the size of the prompt.
For a founder or operator, this is where the cost risk shows up.
A prototype can survive waste.
A production workflow cannot.
If every user request drags half the company knowledge base into the model, the system becomes slow, expensive, and hard to reason about. If the wrong documents enter the prompt, the answer can sound correct while being operationally wrong.
That is worse than a visible failure.
The system needs controls before the model call:
- Request size limits
- Document status checks
- Retrieval filters
- Token budget limits
- Per-tenant rate limits
- Source ranking
- Context deduplication
- Timeout handling
- Fallback answers
- Structured logs
- Human review paths for high-risk outputs
The larger the window gets, the more important the control layer becomes.
A small context system fails because it cannot fit enough information.
A huge context system fails because it can fit too much information without discipline.
The useful architecture is somewhere in the middle: let the model use more context when it genuinely helps, but keep the backend responsible for data shape, source selection, permissions, freshness, cost, and auditability.
That is the lesson I’m taking from the long-context shift.
Bigger windows are useful.
They let the system carry more source material, inspect larger files, work across longer conversations, and reason over broader project state.
But the model should still receive curated context, not a landfill.
The backend still has to know what the data is, where it came from, who can see it, how old it is, how much it costs to send, and how the system can prove what happened afterward.
Infinite context is a tempting interface.
The backend still has to do the work: normalize the data, choose the sources, enforce permissions, cap the request, and leave enough logs to explain the answer later.
Onto the next one. Let’s keep sharpening that edge!
First written on February 26, 2026.
Want to implement this architecture in your business?
Discuss Your Project