The ChatGPT Shift: Conversational State as a Backend Problem
A chat app hit the context limit because the frontend kept sending the full conversation back to the model. The fix was treating conversation history as backend-owned structured state with sessions, turns, summaries, archives, and bounded prompt assembly.
OpenAI launched ChatGPT today, and the reaction is loud for obvious reasons.
The interface feels different. People aren’t just sending one-off prompts anymore. They’re asking follow-up questions, correcting the model, refining answers, and expecting the system to remember the shape of the conversation.
That changes the backend problem.
The API threw a maximum token limit error on turn fifteen.
The chat still looked fine in the browser. The user could scroll through the conversation. The frontend had every message. The failure happened when the app tried to send the entire history back into the model.
Early chat interfaces are using a very simple pattern:
user sends message
→ frontend appends it to chat history
→ full conversation gets sent to the backend
→ backend sends the full prompt to the model
→ model returns the next responseThat works for a short demo. It fails once the conversation becomes real.
A conversation grows every turn. The prompt gets heavier. Latency goes up. Cost goes up. Eventually the payload hits the context window and the model rejects it.
The mistake is treating conversation history like one long text file.
For a backend system, it should be structured state.
Conversation history became database state
I changed the pilot schema around two tables:
- sessions
- turns
The session stores the user/session reference, current summary, active token estimate, status, and timestamps. The turns table stores each user and assistant message as its own row, tied back to the session.
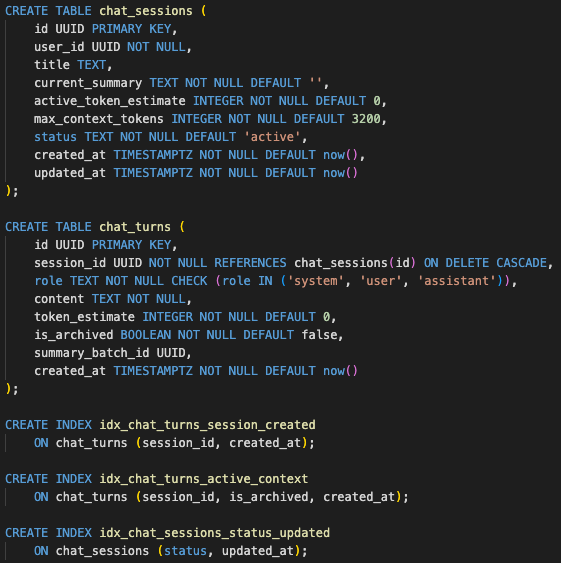
The backend stored conversation history as queryable state instead of trusting the frontend to resend the full chat correctly.
That gave the backend something useful to work with. It could count, trim, summarize, archive, and reconstruct context without trusting the frontend to send the correct history.
The backend assembled bounded context
New request flow:
client sends latest message
→ API loads session
→ API writes the new turn
→ worker checks active token count
→ older turns are summarized when needed
→ backend assembles bounded context
→ model receives summary plus recent turns
→ response is stored as a new turn
The backend owned session state, token budgeting, summaries, and prompt assembly instead of accepting a full chat payload from the client.
The active prompt stopped being “everything the user has ever said.”
It became:
system instructions
→ compressed session summary
→ recent relevant turns
→ latest user messageThat structure gave the system a ceiling. The model still received the useful shape of the conversation, but the backend controlled how much raw history entered the request.
The summary worker controlled the hot path
The summary worker handled the cleanup.
When the active token estimate crossed a threshold, it selected older turns, summarized them into a smaller state block, stored that summary on the session, and marked the raw turns as archived.

The worker compressed older turns into session memory so the prompt could stay bounded without losing the full audit trail.
The raw turns were still stored for audit and debugging. They just weren’t blindly sent into every model call.
That separation mattered.
The database kept the full history.
The prompt only carried what the model needed right now.
It also made cost easier to reason about. Without this boundary, one active user can make every later request more expensive than the last. A chat session becomes a growing payload. With bounded context assembly, each request has a predictable upper range.
The backend contract became clearer
The backend contract became clearer:
- the client sends only the latest message
- PostgreSQL stores the conversation as structured turns
- the worker maintains compressed memory
- the backend assembles the prompt
- the model receives bounded context
- archived turns stay available outside the hot path
This is the part I keep coming back to with language models. The interface looks conversational, but the system underneath still needs normal data engineering.
State has to live somewhere.
Context has to be selected.
History has to be compressed.
Costs have to be bounded.
Failures have to be recoverable.
Result
ChatGPT makes the user experience feel obvious. The backend work behind that experience is still wide open.
If chat becomes the default interface for software, conversation history can’t stay as frontend string concatenation. It needs schemas, workers, summaries, archive rules, token budgets, and prompt assembly controlled by the server.
That is the real systems work starting to show up now.
Onto the next one. Let’s keep sharpening that edge.
First written on November 30, 2022.
Want to implement this architecture in your business?
Discuss Your Project