The Embedding Trap: Why Default Models Need Domain Evals
A legal retrieval pipeline looked healthy until vector search returned the wrong kind of contract. The fix was not prompt tuning. It was a domain-specific retrieval eval, embedding versioning, and a safer migration path.
I’ve been spending more time inside retrieval failures lately. Not the obvious ones where the system returns nothing. The more annoying ones where the system returns something close enough to look right, then sends the model down the wrong path.
This one came from a legal retrieval pipeline.
The vector search returned a catering agreement instead of a non-disclosure clause.
The ingestion side was already in decent shape by this point. PDFs were cleaned. Chunks had metadata. Weaviate was stable. Source text came back with page references and section labels.
The pipeline looked sane:
case files
→ cleaned text chunks
→ embeddings
→ vector database
→ filtered retrieval
→ prompt assembly
→ model answer
The ingestion and retrieval flow looked stable, but the embedding model was still deciding which legal context reached the prompt.
The weak part was the embedding model
The weak part was the embedding model.
I had started with text-embedding-ada-002, mostly because it was the default path everywhere. Tutorials used it. Framework examples used it. Most starter RAG pipelines treated it like plumbing.
That’s dangerous because embeddings feel invisible once the pipeline runs.
You don’t see the embedding model make a bad decision. You see the retrieval result, then you see the language model produce a confident answer from whatever context it was handed.
For this workload, the bad matches were specific. Broad semantic similarity was fine. Dense legal distinctions were the problem.
The system could find “contract-like” documents. It struggled when the query depended on the difference between indemnity, confidentiality, liability caps, termination rights, and disclosure obligations. Those categories live close together in language, but they are not interchangeable in a legal workflow.
A catering agreement and an NDA can share vocabulary:
vendor
agreement
party
confidential
services
term
liabilityThat overlap is enough to confuse a general-purpose retrieval setup if nobody measures it against the actual domain.
I built a retrieval eval
So I stopped treating the embedding model as a default dependency and built a retrieval eval.
Nothing fancy at first. Just a small ground-truth set:
- user query
- expected document
- expected clause or section
- acceptable neighboring chunks
- unacceptable false positives
- notes on why the answer matters
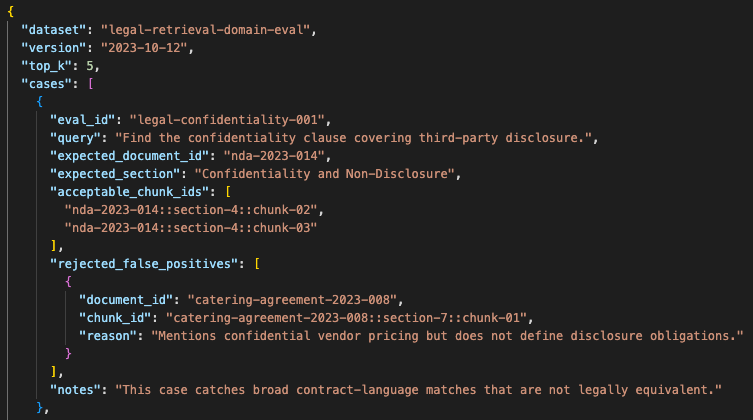
The eval made legal retrieval quality measurable by expected clause, acceptable neighboring chunks, and unacceptable false positives.
Then I tested the current embedding setup against BGE-large.
BGE-large had been released recently and was showing strong benchmark performance on MTEB and C-MTEB. That made it worth testing, but the benchmark wasn’t the deciding factor. The deciding factor was whether it retrieved the right clauses for this legal corpus.
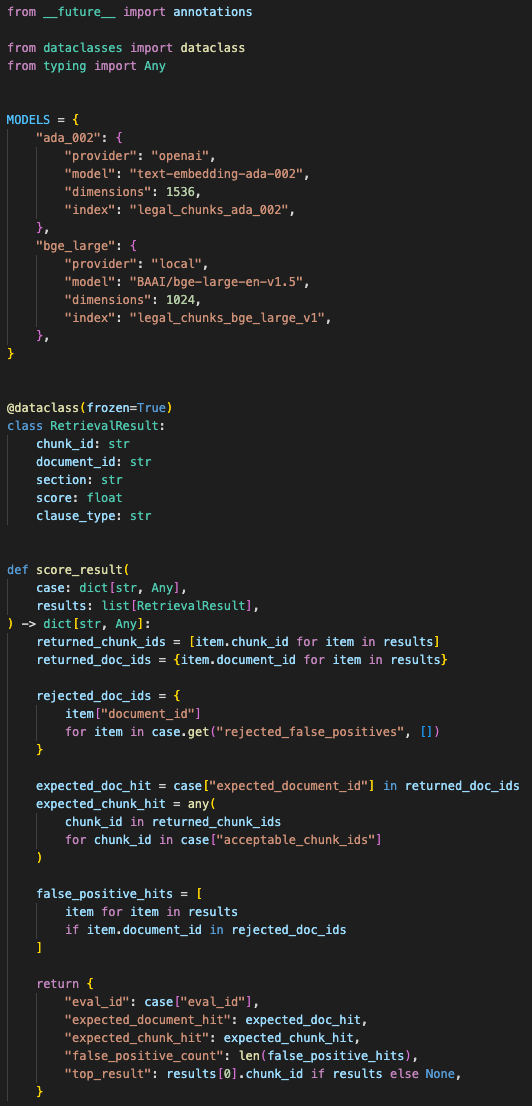
The comparison ran the same domain queries against both embedding setups and logged false positives by clause type.
The eval exposed the real failure pattern
The evaluation changed the conversation.
Instead of arguing whether one embedding model was “better,” I could inspect the failure pattern:
- confidentiality query retrieved a general services clause
- liability-cap query retrieved indemnity language
- termination query retrieved renewal language
- disclosure query retrieved catering or vendor operations text
- exact clause existed but ranked below noisy semantic neighbors
That gave me something concrete to fix.
I deployed BGE-large as a separate embedding service and kept the rest of the retrieval architecture stable. The API didn’t need to know much about the model swap. It still sent normalized chunks to an embedding endpoint and received vectors back. The boundary stayed clean.
The embedding service had its own contract:
- input text
- embedding model version
- vector dimensions
- normalization behavior
- batch size
- latency
- failure reason

The model swap stayed behind a service boundary, with vector dimensions and embedding model version recorded per chunk.
Changing embeddings is a migration
That version field mattered. Once embeddings are stored, changing models is a migration. You can’t safely mix old and new vectors inside the same index and pretend the distances mean the same thing.
So the migration path became:
create new index
→ embed the same cleaned chunks with BGE-large
→ store model version on every vector
→ run retrieval evals
→ compare false positives
→ switch query traffic only after the eval passesThis is where the pipeline started feeling more like normal backend infrastructure again. A model change needed versioning, migration, evaluation, rollback, and logs.
Result
After the swap, the retrieval results improved on the legal eval set. The useful improvement was less about average semantic similarity and more about reducing the specific false positives that made answers unsafe.
The cost profile changed too. Running embeddings through a local or self-hosted service reduced API dependency for ingestion jobs, especially when re-embedding large document sets. But I wouldn’t frame that as “free.” Self-hosted embeddings still cost CPU, memory, deployment time, monitoring, and maintenance.
For this workload, that tradeoff was acceptable.
The lesson I’m taking from this is simple enough: embeddings need evals before they become infrastructure.
The default model might be fine. It might even be the right choice. But once retrieval quality affects legal, financial, or operational decisions, the embedding layer has to be measured against the domain instead of inherited from a tutorial.
For RAG systems, retrieval failure usually starts before the prompt. The model can only answer from the context it receives. If the embedding layer pulls the wrong paragraph, everything downstream becomes cleanup work.
Onto the next one. Let’s keep sharpening that edge.
First written on October 12, 2023.
Want to implement this architecture in your business?
Discuss Your Project