The Generative Trap: Defending Against Probabilistic Outputs
A GPT-2 extraction prototype returned polite prose instead of JSON and crashed the database write path. The fix was a defensive model wrapper with raw output capture, parsing cleanup, schema validation, evidence checks, capped retries, a dead letter queue, and human review.
The downstream database crashed because the model returned a polite paragraph instead of a JSON object.
OpenAI announced its API earlier this month. GPT-3 is now the thing everyone is watching.
The demo energy is understandable. Text in, text out. Prompt the model and it writes, extracts, summarizes, classifies, answers, completes.
That interface is going to tempt developers into a bad backend decision.
They’re going to treat generative models like normal APIs.
I hit the same failure mode yesterday while working with a GPT-2-based extraction prototype on EC2.
The objective was contract extraction.
Take unstructured legal text, identify important clauses, return structured fields, and store the result for review.
The intended path was simple:
contract text
→ model inference endpoint
→ JSON extraction result
→ parser
→ PostgreSQL write
→ review screen
The first version assumed the model would behave like a normal API and return the exact object shape the backend expected.
The first test looked good.
The model identified a liability clause.
The second test hallucinated a termination fee that did not exist in the contract.
The third test ignored the requested JSON shape and returned a bulleted list starting with:
“Here is the data you requested:”
That broke the write path.
The backend expected keys. The model returned prose.
No stable object.
No predictable fields.
No clean database insert.
Just a helpful-looking answer in the wrong shape.
That was the useful failure.
Generative output is not a normal API response
A generative model does not behave like a normal REST endpoint. A normal endpoint has a contract. The response shape is part of the system design.
A language model gives you probable text.
Sometimes that text follows your format. Sometimes it drifts. Sometimes it invents. Sometimes it sounds useful while violating the software contract around it.
The original backend path was too trusting:
send prompt
→ receive text
→ parse as JSON
→ write to database
Parsing raw model text and writing it directly to storage made probabilistic output a database risk.
That path was fine for a demo.
It was too weak for a real extraction workflow.
I added a defensive wrapper
So I added a defensive wrapper around the inference endpoint.
The wrapper became the boundary between probabilistic output and deterministic software.
The new shape looked like this:
contract text
→ prompt builder
→ model inference
→ raw output capture
→ cleanup parser
→ schema validation
→ retry or dead letter queue
→ database write only after validation
The wrapper captured raw output, parsed it, validated it, retried safely, and blocked database writes until the result passed checks.
Prompt discipline helped, but did not solve it
The first fix was prompt discipline.
Loose prompts produced loose outputs. Asking the model to “extract key contract terms” gave it room to explain, summarize, and decorate the answer.
I needed records.
So I moved to few-shot prompting.
The prompt included several examples of the exact input and output pattern:
contract snippet
→ expected JSON
contract snippet
→ expected JSON
contract snippet
→ expected JSON
actual contract snippet
→ model completes the next JSON object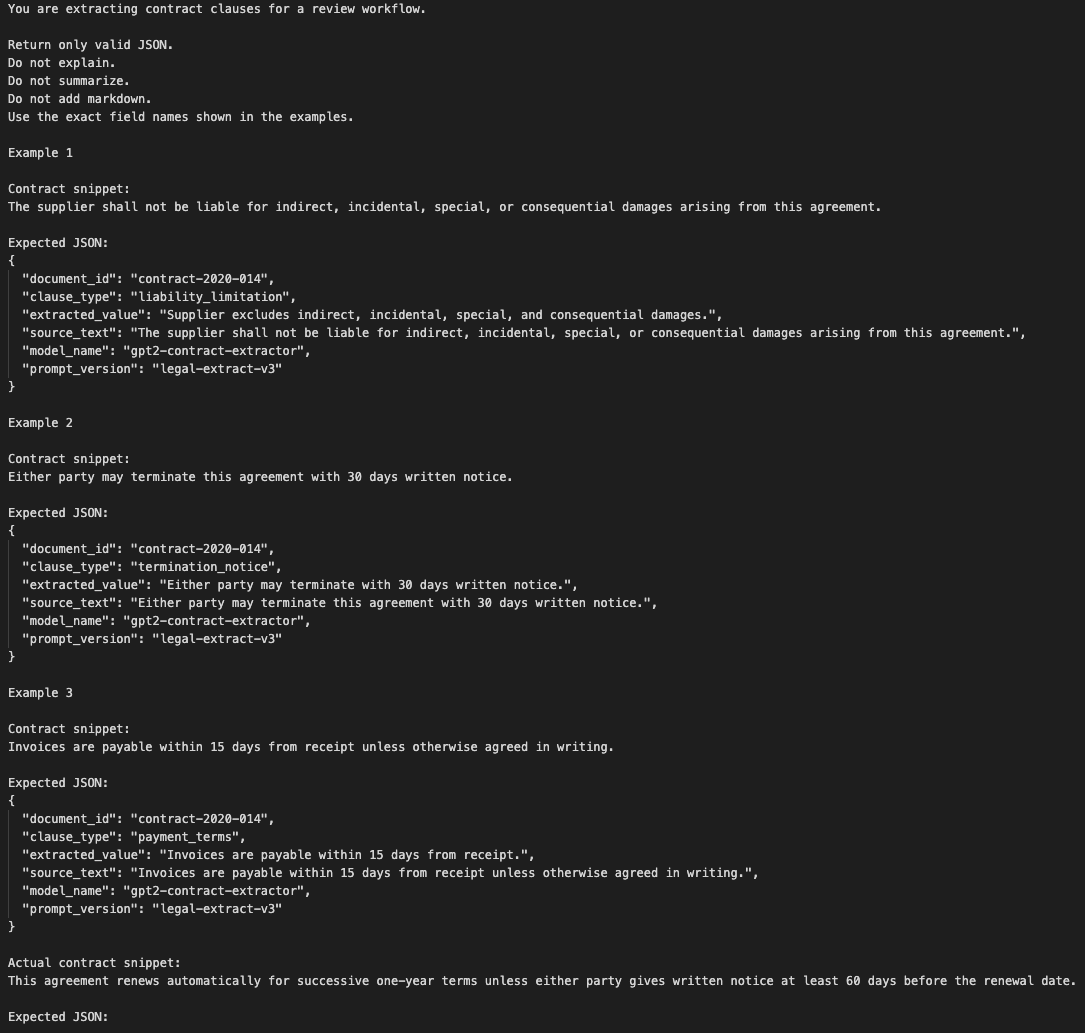
The prompt used boring examples to pressure the model toward a strict extraction shape instead of commentary.
The examples were deliberately boring.
No open-ended instruction.
No analysis request.
No legal commentary.
Just pattern pressure.
That reduced format drift.
It did not remove it.
The model still added filler. Sometimes it changed field names. Sometimes it wrapped the JSON in explanation. Sometimes it returned a valid-looking object with a value that was not supported by the contract text.
So the raw output had to be treated as hostile input.
The parser and schema became the safety boundary
The parser did four jobs:
- capture the raw response
- extract the JSON-like block
- strip conversational filler
- reject anything that could not be parsed cleanly

The parser treated model output as untrusted text and only passed clean objects to validation.
After parsing, the object hit a strict schema.
The extraction record needed:
document_id
clause_type
extracted_value
source_text
model_name
prompt_version
created_at
The extraction schema forced every record to carry model metadata, prompt version, and supporting source text.
The most important field was source_text.
If the model claimed the contract had a termination fee, it had to provide the exact sentence or clause that supported the claim.
No source text, no write.
That rule caught the failure that plain JSON validation would miss.
A valid JSON object can still contain garbage.
Example:
{
"clause_type": "termination_fee",
"extracted_value": "$50,000",
"source_text": "Either party may terminate this agreement with 30 days written notice."
}The object parses.
The shape is valid.
The extracted value is false.
This is where the backend has to stop acting impressed.
The model made a claim. The system needed evidence.
So the review layer showed extracted values beside the source text. The database stored enough context to debug the decision later.
extracted value
source text
document_id
model_name
prompt_version
raw_output_id
The review screen made each model claim inspectable against the exact source text and raw output reference.
Failures became data
Validation failures went through a capped retry path.
First attempt: normal few-shot prompt.
Second attempt: lower temperature.
Third attempt: stricter repair prompt using the validation error.
After that, the payload went to a dead letter queue.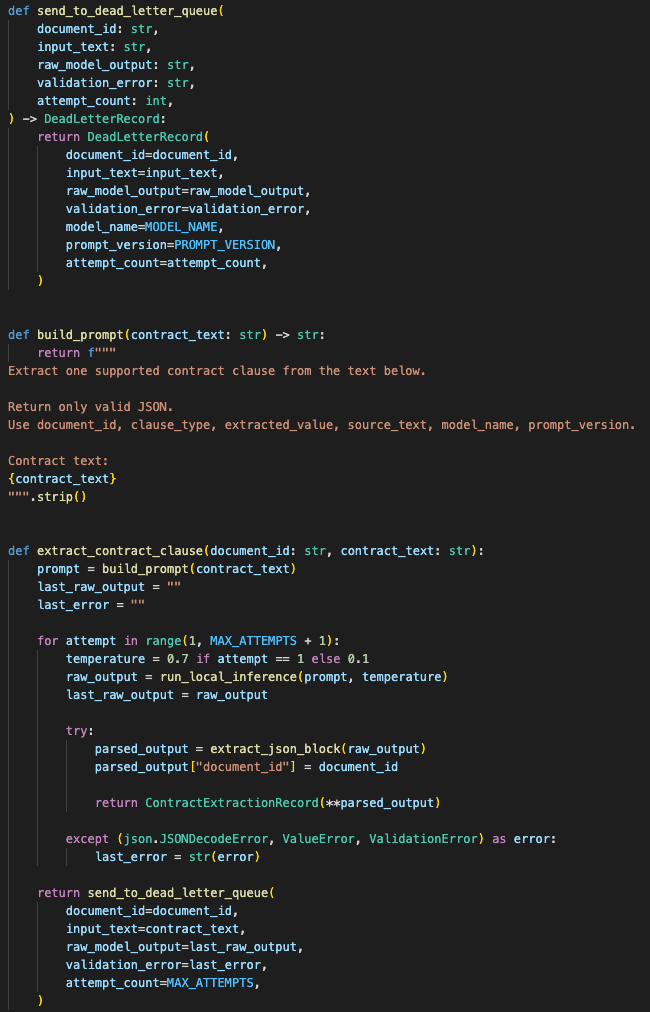
The wrapper capped retries and routed repeated failures into a dead letter queue instead of forcing bad outputs into storage.
The dead letter queue stored:
document_id
input_text
raw_model_output
validation_error
model_name
prompt_version
attempt_count
created_at
Failed generations became reviewable data instead of disappearing into logs or crashing the write path.
That queue became useful quickly.
It showed which clauses made the model drift. It showed where the prompt examples were too weak. It gave me actual failed outputs to improve against.
Logs were not enough here. Failed generations needed to become a dataset.
The final path was less fragile:
contract text
→ prompt builder
→ GPT-2 inference endpoint
→ raw output log
→ parser
→ Pydantic schema validation
→ evidence check
→ capped retry
→ dead letter queue
→ human review
→ PostgreSQL write
The final system converted model text into data only after parsing, validation, evidence checks, and reviewable failure handling.
Result
This is the part I think will matter as larger models arrive.
GPT-3 will make the output look much better. That does not remove the backend problem.
A smoother answer can still break a parser. A more fluent answer can still invent a value. A bigger model can still drift away from the format the database expects.
The engineering work sits at the boundary:
- prompt templates
- raw output capture
- parsing cleanup
- schema validation
- source text requirements
- prompt versioning
- model versioning
- capped retries
- dead letter queue
- human review path
That is the system that keeps probabilistic text from corrupting deterministic software.
The model can generate.
The backend has to decide what becomes data.
Onto the next one. Let’s keep sharpening that edge.
First written on June 28, 2020.
Want to implement this architecture in your business?
Discuss Your Project