Using a Model to Audit Label Quality at Scale
A document classifier stalled at 0.74 F1 because the training labels were wrong. The fix was a separate label-audit workflow with out-of-fold predictions, confidence disagreement filters, a review queue, correction records, and reproducible cleaned exports.
I lost three days tuning a document classification model before the real problem showed up in the pipeline.
The classifier was part of a larger records-routing system. Text records came in, passed through a controlled category taxonomy, and moved downstream based on the assigned class. The model sat inside a backend flow, so a bad prediction was not just a weak metric. It could route work into the wrong queue.
The baseline F1 score was stuck around 0.74. I changed the learning rate, adjusted dropout, swapped the encoder, and reran training jobs. Nothing moved enough to matter.
The first system shape was simple:
text records
→ human labels
→ training dataset
→ classifier
→ routing queue
The classifier was not just producing a metric. Its output moved records into downstream operational queues.
The strange cases came from label disagreements
The strange cases came from high-confidence disagreements.
I sorted the training set by loss and pulled rows where the model strongly disagreed with the assigned label. The records were not random edge cases. A noticeable number had labels that did not match the taxonomy rules.
The training script had treated every label as truth. The backend had no audit path between labeled data and production routing.
That was the system gap.
The first flow looked like this:
labeled records
→ training job
→ model artifact
→ deployment
→ routing decisions
The production classifier inherited label mistakes because there was no audit boundary before training.
I built a separate label-audit pipeline
I needed a way to audit label quality without manually reading the whole dataset.
So I built a separate label-audit pipeline. It was not the production classifier. It was a temporary backend workflow for finding rows that deserved review.
The audit flow looked like this:
training dataset
→ K-fold split
→ temporary classifier runs
→ out-of-fold predictions
→ confidence disagreement filter
→ review queue
Out-of-fold predictions let each record be scored by a model that had not trained on that same record.
Out-of-fold predictions kept the audit cleaner. Each record had to be scored by a model that had not trained on that record.
For every row, the pipeline stored:
record_id
original_label
predicted_label
prediction_confidence
fold_id
audit_run_id
model_version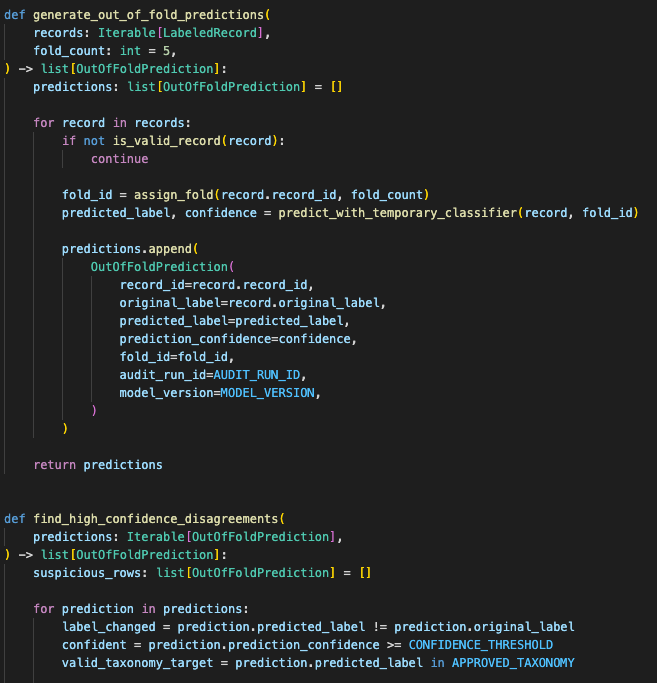
The audit job created fold-level predictions, filtered suspicious rows, and wrote review candidates into a durable table.
The first useful filter was strict:
- prediction confidence above 0.90
- prediction disagreed with the assigned label
- record text passed validation
- predicted category existed in the approved taxonomy
That produced around 4,200 suspicious records.
The review queue needed a real backend
A spreadsheet would have broken the cleanup work. Too many rows, too easy to duplicate decisions, lose edits, or overwrite someone else’s review. I built a small Streamlit review tool backed by a correction table.
The UI stayed basic:
record text
original label
model-proposed label
confidence score
accept or keep action
The interface was simple because the important part was preserving each review decision as durable data.
The backend around it mattered more than the screen. Each review action wrote a durable correction record:
record_id
original_label
proposed_label
review_decision
reviewed_by
reviewed_at
audit_run_id
model_version
The original labels stayed intact. Accepted corrections lived in a separate table with reviewer and audit-run metadata.
That gave the cleanup process a real data trail. The original labels stayed intact. Corrections were stored separately. The cleaned dataset could be rebuilt from the source records plus accepted corrections.
The same model improved after the data was fixed
The review queue moved quickly. The proposed correction was accepted around 88% of the time.
After applying accepted corrections, I retrained the same baseline classifier. Same general architecture. Same training setup. Cleaner input data.
F1 moved from around 0.74 to around 0.92.

The quality jump came from cleaning the training labels, not from another model tweak.
The final architecture became:
raw records
→ initial labels
→ audit job
→ out-of-fold predictions
→ suspicious row table
→ review tool
→ correction table
→ cleaned dataset export
→ production classifier training
→ routing serviceThe model became one step inside a repeatable label-quality pipeline with review state and export rules.
Result
This was backend work wearing an ML costume.
The model helped find inconsistent labels, but the useful system was the pipeline around it: audit runs, review queues, correction tables, reproducible exports, model metadata, and clean handoff back into training.
That changed the project from “tune the classifier again” into “build a repeatable label-quality workflow.”
The quality jump came from treating labels as operational data with failure modes, ownership, and history.
Onto the next one. Let’s keep sharpening that edge.
First written on February 24, 2021.
Want to implement this architecture in your business?
Discuss Your Project