Vector Storage Costs in Document Retrieval Systems
A legal retrieval prototype worked quickly with Pinecone, but the cost and metadata shape did not fit the workload. Moving the storage boundary to Weaviate simplified retrieval, source traceability, debugging, and cost control.
I’ve been spending more time on document retrieval systems lately. Legal files, case notes, contract folders, policy documents, all the boring text that suddenly becomes useful once you can search it semantically.
The prototype phase is fun. Embed the text, store vectors, ask questions.
The production bill is less fun.
The vector storage cost came in higher than expected.
This was for a legal document retrieval pipeline. The system ingests case files, extracts text, chunks the documents, embeds the chunks, then searches those vectors when a user asks a question.
The first version used Pinecone because it was fast to wire up.
The shape was clean:
case files
→ text extraction
→ cleaned chunks
→ embeddings
→ Pinecone vector index
→ retrieve chunk IDs
→ fetch text from PostgreSQL
→ assemble context
→ model answer
Pinecone made the prototype fast to build, but the backend still needed a second source-text lookup before prompt assembly.
That got the system working quickly. API key, index, upsert, query. Very low friction.
The cost problem showed up in the access pattern
The cost problem showed up once the access pattern became clearer.
This system had a large document base, but search traffic was uneven. Some days had bursts. Some days were quiet. The vector index still had to stay available. So the bill was tied less to “how much useful search happened today” and more to keeping retrieval infrastructure warm enough to answer quickly when someone needed it.
That is a reasonable tradeoff for high-volume products.
For this workload, it was expensive for the amount of actual search traffic.
The second issue was the data shape. Pinecone handled vector search well, but the retrieval result still needed the source text. The metadata payload was too constrained for the way I wanted to store cleaned legal chunks, page references, section labels, and review fields together.
So the app had a second hop:
Pinecone returns vector matches
→ backend extracts chunk IDs
→ PostgreSQL fetches readable text
→ backend rebuilds source context
→ prompt gets assembledThat extra hop wasn’t catastrophic. It just made the system more complicated than it needed to be.
I moved the storage boundary to Weaviate
I tested Weaviate as the storage boundary instead.
Pinecone was easier to start with. Weaviate gave me more control over the shape of the system.
With Weaviate, the object and vector could live together. The searchable item could carry the text chunk, source metadata, document reference, page range, and vector in one place.
The retrieval path became simpler:
case files
→ text extraction
→ cleaned chunks
→ embeddings
→ Weaviate object with vector and text
→ retrieve matching objects
→ assemble context
→ model answer
Storing vectors and source text together made retrieval results usable immediately during prompt assembly.
The migration work was mostly schema mapping.
I had to define the document object properly:
- document ID
- case or matter ID
- chunk text
- page range
- section heading
- chunk index
- embedding model version
- source file reference
- access scope
- created timestamp
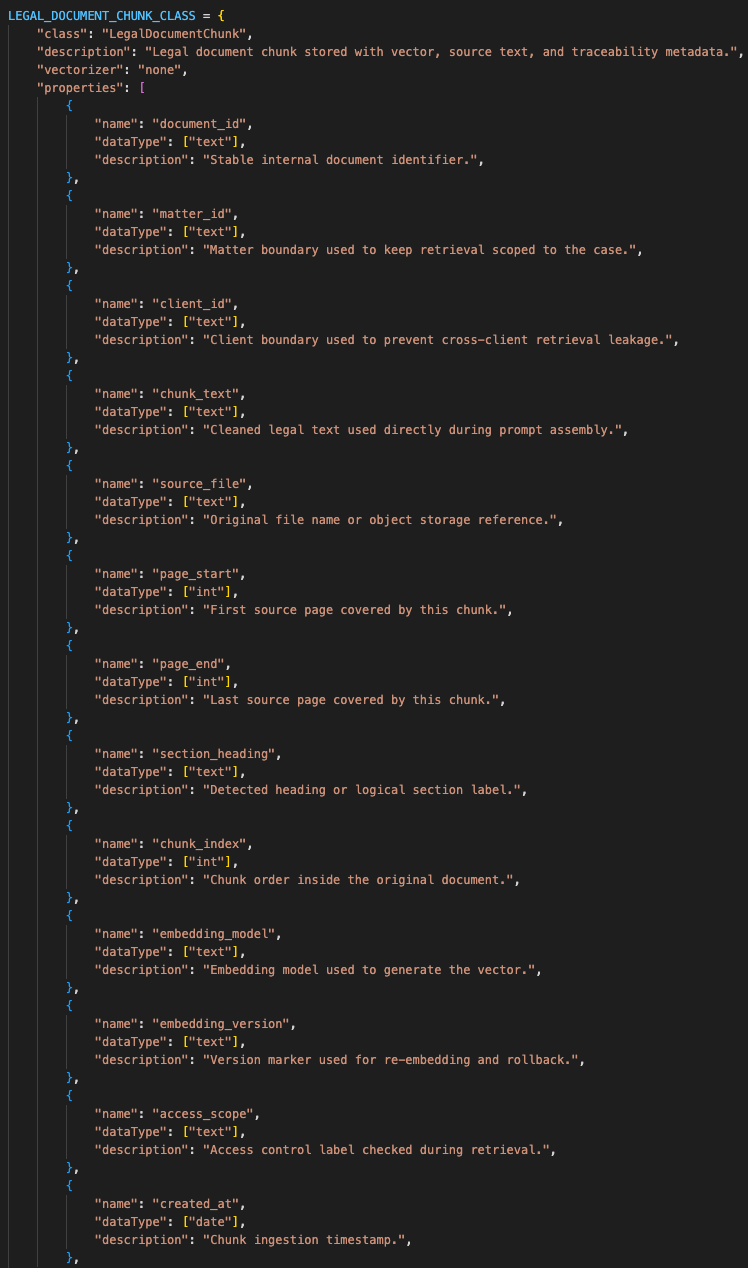
The schema made source traceability, access scope, page range, and embedding version part of the retrieval object.
That schema work felt slower than the Pinecone setup at first. Pinecone let me move fast with fewer decisions. Weaviate forced the storage model into the open.
For this kind of system, that was useful.
Legal retrieval needs more than nearest-neighbor search. It needs source traceability, filtering, access rules, document grouping, and enough metadata to explain why a chunk was retrieved. If the vector database only gives back an ID, the backend has to rebuild the rest of the context somewhere else.
The query returned usable context objects
The query path changed too.
Instead of treating vector search as a detached lookup, the retrieval step started returning usable context objects:
matched chunk
source document
page range
section heading
score
text
metadata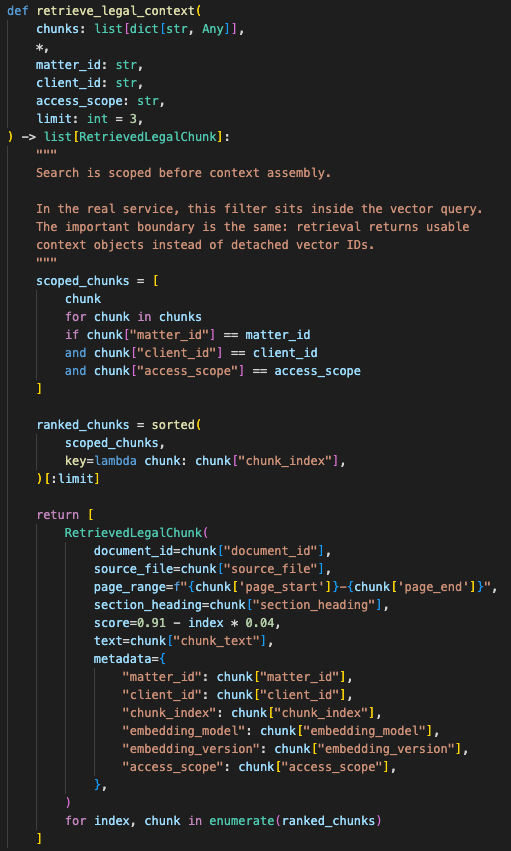
The query returned chunk text and source metadata together, which made prompt assembly and debugging simpler.
This made debugging easier. When the model gave a weak answer, I could inspect the retrieved objects directly instead of jumping between vector IDs and PostgreSQL rows.
The tradeoff was setup friction versus ownership
The operational tradeoff became clear.
Pinecone reduced setup friction.
Weaviate increased ownership.
Running Weaviate meant thinking about Docker deployment, storage volumes, schema changes, backups, memory use, and index tuning. That is real work. But it also meant the system could be shaped around the workload instead of shaping the workload around a hosted index.
For this pipeline, the simpler retrieval path mattered more than the easiest onboarding.
Result
After the migration, the architecture had fewer moving parts during prompt assembly. The backend no longer had to bounce from vector search into a second source-text lookup for every result. Cost also became easier to reason about because storage and compute decisions were closer to the actual workload.
The lesson here is mostly about access patterns.
A high-traffic semantic search product can justify managed vector infrastructure more easily. A legal retrieval system with large storage, uneven search volume, strict metadata needs, and source traceability may need a different shape.
Vector databases are infrastructure. The right choice depends on what the system actually does all day:
- how many vectors sit idle
- how often users search
- how much metadata travels with each chunk
- how source text is retrieved
- how access control is applied
- how much operational ownership the project can tolerate
For this build, owning more of the storage layer made the backend simpler where it mattered: retrieval, context assembly, debugging, and cost control.
Onto the next one. Let’s keep sharpening that edge.
First written on May 12, 2023.
Want to implement this architecture in your business?
Discuss Your Project